La información del calibre y distribución por tallas del pescado en primera venta es un dato de gran importancia tanto a nivel comercial como de gestión de los recursos marinos
La Universitat Politècnica de Catalunya (UPC) colabora con diferentes Cofradías de Pescadores de Cataluña con el objetivo de realizar un proyecto piloto consistente en un sistema computer vision que aprovecha los avances de Deep Learning para calibrar automáticamente los ejemplares de pescado y extraer datos de tamaño y frescura.
El desarrollo de este está liderado por los profesores Vicenç Parisi, José Antonio Soria y Lluís Ferrer.
Introducción
La preservación de los recursos pesqueros y el mantenimiento y mejora de la actividad económica a su alrededor es fundamental para la sociedad.
Los estudios científicos y gubernamentales sobre el estado de los stocks de pesca coinciden, junto con los datos estadísticos en nuestro país, en la tendencia decreciente de la evolución de las capturas. Y, aunque los precios del pescado han aumentado, los ingresos reales de los pescadores siguen disminuyendo.
Todo ello pronostica la desaparición futura, tanto de los recursos pesqueros, como de la actividad en su entorno si no se actúa adecuadamente.
Para garantizar la continuidad de estos recursos y mejorar la eficiencia de la industria pesquera y la economía de las sociedades costeras, la Unión Europea ha estado introduciendo a lo largo de los últimos años una serie de medidas, planes de gestión, limitaciones de pesca y requerimientos ambientales que necesitan datos reales y detallados sobre capturas para poder analizar correctamente la situación.
Los efectos positivos de tener calibrados los productos pesqueros son muy importantes:
Permiten y mejoran las transacciones comerciales entre operadores situados en mercados diferentes.
Posibilitan la venta por internet con mayor detalle.
Ayudan a implementar los planes de gestión de la actividad pesquera.
Reducen la comercialización de pescado por debajo de la talla mínima reglamentaria.
El proyecto de la UPC
La teoría
El principal objetivo de este proyecto es, pues, determinar estos calibres de una manera más eficiente y exacta y diseñar sistemas que permitan calibrar un mayor número de ejemplares.
Los sistemas basados en Deep Learning utilizan modelos de redes neuronales artificiales que emulan el comportamiento de las neuronas, pudiendo aprender patrones complejos.
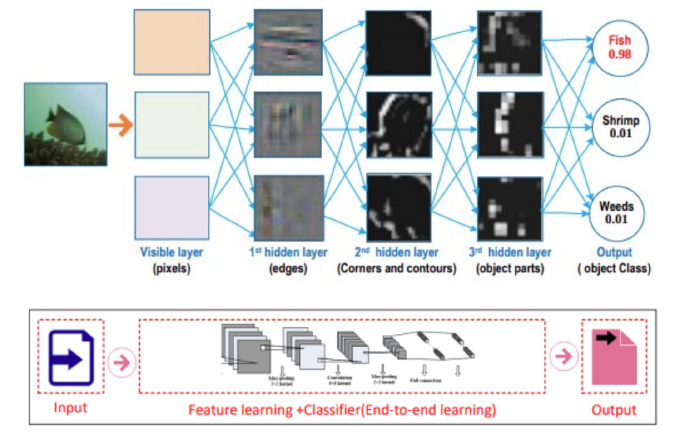
En este sentido, existe una arquitectura de Deep Learning llamada Convolutional Neural Network (CNN) que ha dad muy buenos resultados en el reconocimiento de objetos en imágenes.
En dicha arquitectura la información de cada imagen se procesa en distintas capas:
Las primeras capas aprenden a reconocer rasgos primitivos básicos, como líneas.
Las capas intermedias combinan estos rasgos básicos para formar siluetas, esquinas o partes de objetos.
Las últimas capas aprenden a ordenar estas partes para formar un objeto o hacer una clasificación.
Ejemplo de procesamiento de imagen con CNN: Las primeras etapas extraen las características básicas («features») de la imagen y las últimas etapas clasifican el objeto. Fuente: UPC
La práctica
En resumen, lo que pretende la UPC con este proyecto es desarrollar un sistema basado en computer vision, utilizando metodologías Deep Learning para clasificar las especies pesqueras en las lonjas.
Este sistema tiene el objetivo de determinar el calibre (relación tamaño-peso) para alertar de la presencia de ejemplares por debajo de la talla mínima de referencia, así como ayudar a reconocer ejemplares dañados.
En la implementación, una de las mejores formas de extraer el calibre es realizar una segmentación (identificación) de los píxeles que conforman cada especie.
Detección mediante CNN de los píxeles correspondientes a cada ejemplar. Fuente: UPC
A partir de esta segmentación de ejemplares y de la resolución de la imagen (píxeles/mm2) se pueden obtener medidas del área, el perímetro y la longitud de todo el ejemplar (o de las partes visibles si hay oclusiones); así como determinar si existen ejemplares dañados.
Para conseguir esto, es necesario seguir los siguientes pasos:
Segmentar manualmente la base de datos de imágenes para crear un conjunto de entrenamiento, test y validación del sistema.
Entrenar la red neuronal y refinar los parámetros.
Calcular las longitudes de los ejemplares de interés.
Finalmente, cuando el proyecto se lleve a la lonja, se instalará una cámara y un ordenador que informará de la distribución por calibres de las cajas de pescado. Además, se recogerán datos, como el precio de venta, el peso o la temperatura, para realizar un análisis posterior de los resultados obtenidos.
Beneficios del proyecto
Fomento de la pesca sostenible: el comprador tendrá más información del producto y su calidad; al mismo tiempo, se elegirán mejor las especies capturadas (evitando, de este modo, pescar ejemplares por debajo de determinado calibre).
Eficiencia en el uso de los recursos: las actividades o días de pesca se planificarán mejor a lo largo del año, manteniendo así la relación calidad-precio.
Innovación: se aplicarán tecnologías de última generación a un sector con prácticas bastante tradicionales.
Competitividad: permitirá una mejor comercialización a distancia por internet y dará un valor añadido a los productos pesqueros.
Actividad basada en conocimiento: se recogerán datos muy importantes para realizar análisis y monitorización útiles, tanto en la gestión como en la comercialización de la pesca. Además, se podrá automatizar y escalar la recogida de datos.
La aportación de Azken para la UPC
Para desarrollar este proyecto con éxito es necesario un hardware lo suficientemente potente como para poder entrenar bien las CNN en el menor tiempo posible y para poder detectar los peces en tiempo real.
La UPC escogió a Azken Muga como proveedor de soluciones hardware. Concretamente, la máquina elegida para el desarrollo del proyecto fue una M-Series DX-21.
Hace una semanas, hablábamos de HPC o Computación de Alto Rendimiento. En el post de hoy, lo hacemos de rendering, un tipo de computación que, a diferencia de la anterior, da mucha más importancia a la imagen que a los datos.
Veamos en qué consiste el rendering y qué tipos y técnicas lo componen:
¿Qué es rendering?
Rendering, render o renderizado es un concepto muy utilizado en computación que hacer referencia a la transformación de un modelo 3D en una imagen realista 2D.
En otras palabras, es el proceso de obtención de imágenes digitales extraídas de un modelo tridimensional a través de un software dedicado. La finalidad de estas imágenes es simular un objeto o un ambiente de manera fotorrealista.
Este término, que suele ser utilizado en su versión inglesa, es frecuente, sobre todo, en la jerga de los profesionales de la animación audiovisual y los diseñadores 3D; aunque la traducción que mejor se puede ajustar al castellano es «interpretación», haciendo referencia a que la computadora interpreta una escena tridimensional y la representa en una imagen bidimensional.
Una de las partes más importantes del rendering es el motor de renderizado, gracias al cual, es posible imitar un espacio real formado por distintos materiales, texturas, colores, estructuras poligonales, iluminación, reflexión, refracción y ray tracing.
Tipos de rendering
Los principales tipos de rendering son los siguientes:
Renderización en tiempo real
Las imágenes se calculan a tal velocidad, que el proceso de conversión de los modelos 3D en imágenes 2D sucede en tiempo real.
Este tipo de rendering se utiliza mucho en los videojuegos y en gráficos interactivos.
Renderización offline
En este caso, la velocidad no es esencial, por lo que el proceso se lleva a cabo a través de cálculos realizados normalmente con CPUs multi-core.
La característica principal de este tipo de rendering es que, a diferencia del anterior, no existe la imprevisibilidad.
Por eso, es más común en proyectos de animación mucho más complejos visualmente y con un alto nivel de fotorrealismo.
Técnicas de visualización de rendering
Existen cinco técnicas principales de visualización en el renderizado. Veámoslas a continuación:
Scan line
Es una de las técnicas más antiguas. Se encarga de fusionar el algoritmo que determina las superficies con el algoritmo que determina las sombras de las mismas. Por otro lado, trabaja con una línea de escaneo a la vez.
Z-Buffer
Se trata de un algoritmo que determina las superficies visibles.
Utiliza las siguientes estructuras de datos:
z-buffer: para cada pixel, mantiene la coordenada z más cercana al espectador.
frame-buffer: contiene los datos relativos a los colores de los pixeles del z-buffer.
Esta técnica solo se puede aplicar en un polígono cada vez (cuando escanea un polígono, no se puede acceder a la información del resto).
Ray casting
Detecta las superficies visibles y funciona de la siguiente manera: hace partir los rayos del ojo (un rayo por cada píxel) y encontrar el primer objeto que bloquea ese recorrido. Además, es capaz de gestionar superficies sólidas, como esferas o conos.
Por ello, si un rayo alcanza una determinada superficie, esta se podrá diseñar gracias al ray casting.
Ray tracing
Funciona de manera muy parecida al ray casting, pero añadiendo un modelo de iluminación a la escena que tiene en cuenta las reflexiones y las refracciones que experimenta la luz. Esto hace que se consigan unos impresionantes resultados fotorrealistas.
En resumen, el ray tracing simula el recorrido que hace la radiación luminosa hasta llegar al espectador.
Radiosity
Añade todavía más fotorrealismo a la escena al tener en cuenta la inter reflexión entre los diferentes objetos que se encuentran en la misma.
Por ejemplo, cuando una superficie tiene un componente de luz reflectora, esta técnica es capaz de conseguir que esta superficie (por su fenómeno físico de reflexión) ilumine también las superficies cercanas a ella.
Rendering en Azken Muga
En Azken Muga integramos los últimos avances tecnológicos de cálculo distribuido y certificamos las arquitecturas con los principales motores de Render.
Proveemos de soluciones de render a los mejores estudios de animación y VFX nacionales.
2Do espacio bidimensional: módulo geométrico de la proyección plana y física del universo donde vivimos. Tiene dos dimensiones (ancho y largo), pero no cuenta con profundidad. Los planos son bidimensionales y solo pueden contener cuerpos unidimensionales o bidimensionales.
3D o espacio tridimensional: espacio que cuenta con tres dimensiones: anchura, largura y altura (o profundidad).
Computación: área de la ciencia que se encarga de estudiar la administración de métodos, técnicas y procesos con el fin de almacenar, procesar y transmitir información y datos en formato digital.
Píxel: es la menor unidad homogénea en color que forma parte de una imagen digital.
La computación de alto rendimiento (HPC – High Performance Computing) es la capacidad de procesar datos y realizar cálculos complejos a gran velocidad utilizando varios ordenadores y dispositivos de almacenamiento.
Comparativamente, un equipo de sobremesa con un procesador de 3 GHz puede realizar unos 3.000 millones de cálculos por segundo, mientras que, con las soluciones HPC, se pueden realizar cuatrillones de cálculos por segundo.
De esta forma, un servidor para HPC es capaz de resolver algunos de los principales problemas en el mundo de la ciencia, la ingeniería y los negocios mediante simulaciones, modelos y análisis. Algunos ejemplos son: el descubrimiento de nuevos componentes de medicamentos para combatir enfermedades como el cáncer, la simulación de dinámicas moleculares para la creación de nuevos materiales o el pronóstico de cambios climáticos.
Los tipos de soluciones HPC más conocidos son:
Computación paralela. Es un conjunto de sistemas simples con varios procesadores trabajando simultáneamente sobre la misma tarea.
Computación distribuida. Es una red de ordenadores conectados que funcionan de manera colaborativa para realizar diferentes tareas.
Computación en malla o Grid. Es un sistema de computación distribuida que coordina computadoras de diferente hardware y software para procesar una tarea con gran cantidad de recursos y poder de procesamiento.
¿Cómo funciona la HPC?
Para procesar la información en HPC, existen dos métodos principales: el procesamiento en serie y el procesamiento en paralelo. Veamos cada uno de ellos.
Procesamiento en serie
Es el que realizan las unidades de procesamiento central (CPU). Estas dividen una gran carga de trabajo compartida en tareas más pequeñas que se comunican continuamente. Cada núcleo de CPU realiza solo una tarea a la vez. Una de las funciones del procesamiento en serie es la ejecución de aplicaciones básicas como el procesamiento de textos.
Procesamiento en paralelo
Es el que realizan la unidades de procesamiento gráfico (GPU). Estas son capaces de realizar diferentes operaciones aritméticas de forma simultánea por medio de una matriz de datos. Las cargas de trabajo paralelas son problemas de computación divididos en tareas sencillas e independientes que se pueden ejecutar a la vez sin apenas comunicaciones entre ellas. Una de las funciones del procesamiento en paralelo es la ejecución de aplicaciones de aprendizaje automático (Machine Learning), como el reconocimiento de objetos en vídeos.
El futuro de la HPC
Cada vez más empresas e instituciones están recurriendo a la HPC. Como resultado, se prevé que el mercado de este tipo de servidores crezca hasta los 50.000 millones de dólares en 2023. Además, gran parte de ese crecimiento se verá reflejado en la implementación de la HPC en la nube, que reduce de forma considerable los costes de una empresa al no ser necesaria la inversión en infraestructuras de centros de datos.
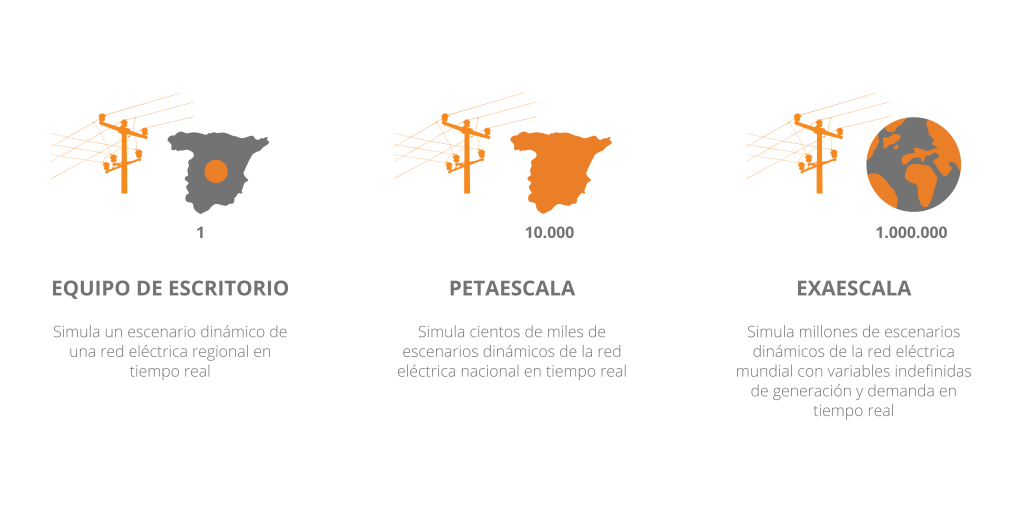
De igual forma, gracias a los avances tecnológicos tanto en procesamiento como en rendimiento, pronto se dará un nuevo paso en la era de la supercomputación: la exaescala, con la que se podrán realizar 10^18 (1.000.000.000.000.000.000) operaciones por segundo.
HPC en Azken Muga
Finalmente, incorporando la tecnología más avanzada en proceso, conectividad y almacenamiento, los servidores de Azken Muga satisfacen las necesidades de sus clientes, que buscan acelerar sus resultados de negocio con una infraestructura optimizada y realizar sus tareas de manera más rápida, fiable y asequible.
Es un superordenador en formato rack 4U de doble zócalo que admite hasta diez tarjetas GPU de alto rendimiento. Con dos procesadores Intel Xeon Scalable de tercera generación y 32 módulos DIMM DDR4, proporcionando una extraordinaria potencia de cálculo heterogénea para una gran variedad de aplicaciones de computación científica de alto rendimiento basadas en la GPU, entrenamiento de IA, inferencia y aprendizaje profundo. Un servidor concebido para balancear mas de 190 TeraFlops en doble precisión. La mejor combinación de proceso CPU, almacenamiento y proceso paralelo sobre GPU, una arquitectura ideal que alberga hasta 10 GPUs NVIDIA® de última generación.
Servidor en formato rack de 4U equipado con procesadores AMD EPYC™ 9004 series de doble socket, hasta 192 núcleos Zen 4, 12 canales por socket de memoria RAM DDR5 hasta 4800 MHz y con el mayor rendimiento de conmutación con PCIe 5.0. Diseñado para las demandas de la infraestructura de IA empresarial con el fin de ofrecer un rendimiento sin precedentes con GPU´s líderes del segmento, una interconexión de GPU más rápida, un mayor ancho de banda, la cual admite una configuración escalable de hasta ocho GPU´s activas o pasivas de doble slot con la opción de NVIDIA NVLink® Bridge o AMD Infinity Fabric™ Link para permitir el escalado del rendimiento, lo que permite adaptarse a sus cargas de trabajo de IA y HPC.
GLOSARIO
Supercomputadora: el tope de gama en HPC, según la evolución de los estándares de rendimiento.
Computación heterogénea: arquitectura de HPC que optimiza las capacidades de procesamiento en serie (CPU) y en paralelo (GPU).
Memoria: donde se almacenan los datos en un sistema HPC para acceder a ellos rápidamente.
Petaescala: supercomputadora diseñada para realizar mil billones (10^15) de cálculos por segundo.
Exaescala: supercomputadora diseñada para realizar un trillón (10^18) de cálculos por segundo.
FLOPS: unidades de potencia de procesamiento de las computadoras (operaciones de punto flotante por segundo). “FLOPS” describe una velocidad de procesamiento teórica: para hacer posible esa velocidad es necesario enviar datos a los procesadores de forma continua. Por lo tanto, el procesamiento de los datos se debe tener en cuenta en el diseño del sistema. La memoria del sistema, junto con las interconexiones que unen los nodos de procesamiento entre sí, impactan en la rapidez con la que los datos llegan a los procesadores.
El funcionamiento e interacción de las biomoléculas es fundamental para comprender las enfermedades, desarrollar nuevos fármacos y la administración de tratamientos médicos.
La microscopía electrónica criogénica (cryo-EM) es un método de obtención de imágenes que permite la observación directa de las proteínas en estado nativo o casi nativo sin tintes ni fijadores, lo que permite a los investigadores estudiar las estructuras celulares, los virus y los complejos proteicos con detalle molecular.
Esta reconstrucción de estructuras tridimensionales y de resolución casi atómica de biomoléculas suele requerir miles de imágenes y una compleja computación, lo que dificulta la obtención de estructuras de alta resolución.
La crioelectrónica puede ayudar a superar este reto. Su éxito dependerá de una mayor adopción, del aumento del tamaño de los datos, de la maduración del mercado y del auge del deep learning.
CONJUNTOS DE DATOS MASIVOS
El alcance y la complejidad de los datos de cryo-EM han aumentado enormemente con los avances en la automatización y la tecnología visual. Las cámaras con mayor sensibilidad capturan imágenes a velocidades de cuadro más rápidas. Con la mejora de la preparación de las muestras, la automatización de la adquisición de datos y los tiempos de funcionamiento de los instrumentos, los requisitos para el procesamiento de datos y la computación siguen aumentando.
Por ejemplo, en un experimento típico, a menudo se necesitan entre 1.000 y 8.000 imágenes, capturadas a partir de 4 a 8 terabytes (TB) de datos de imágenes sin procesar, para generar mapas de alta resolución de una sola partícula.
En los últimos años, casi todos los pasos de los flujos de trabajo de una sola partícula que requieren un gran esfuerzo informático de trabajo de una sola partícula se han adaptado para aprovechar los procesadores de la GPU, que acortan drásticamente los tiempos de procesamiento. Para seguir el ritmo del aumento del tamaño de los datos, las aplicaciones de crioelectrónica deben optimizarse para las GPU de gama alta.
LA MADURACIÓN DEL MERCADO
Tradicionalmente, el procesamiento de los datos de las imágenes criogénicas para descubrir las estructuras de las proteínas y crear mapas 3D de alta resolución requiere la intervención de expertos, conocimientos estructurales previos y semanas de cálculos en costosos clusters informáticos.
A medida que se generaliza, la crioelectrónica está fomentando la demanda de software comercial, de grado comercial y no experto. Estas soluciones de software implican el uso de algoritmos para automatizar tareas especializadas y que requieren mucho tiempo.
INFUSIÓN DE EL DEEP LEARNING
La selección de partículas de proteínas individuales en micrografías de cryo-EM es un paso importante en el análisis de partículas individuales. Es un reto identificar las partículas debido a la baja relación señal-ruido y a las enormes variaciones que se producen en los complejos macromoleculares biológicos.
Aprovechando el aprendizaje sin etiqueta positiva, un pequeño número de ejemplos de proyecciones de proteínas puede entrenar una red neuronal para detectar proteínas de cualquier tamaño o forma. Topaz, una aplicación de código abierto con esta capacidad, detecta muchas más partículas que otros métodos de software sometidos a prueba. Gracias a las GPU de NVIDIA, se reduce drásticamente la cantidad de datos que hay que etiquetar manualmente.
LAS GPUs EN EL WORKFLOW DE CRYO-EM
Los métodos de cryo-EM están abriendo oportunidades para explorar la complejidad de las estructuras macromoleculares de formas antes inconcebibles. Desde los sistemas de investigación en fase inicial hasta los grandes centros de datos, las GPU están permitiendo acelerar el flujo de trabajo de principio a fin. Al optimizar las cargas de trabajo clave para la adquisición de datos y la reconstrucción de una sola partícula, las GPU siguen proporcionando vías para lograr avances científicos y sanitarios.
Con el cálculo basado en la GPU y el aprendizaje profundo, los avances en la crioelectrónica aumentarán su fiabilidad y rendimiento y, en última instancia, su adopción y éxito.
T-Series Cryo-EM
PresentamosT-Series Cryo-EM, una estación de trabajo equipada con las últimas GPUs de NVIDIA® RTX™, con procesadores Intel® Xeon® Scalable Processors y la preinstalación de una pila de software orientado a la Microscopía Electrónica.
Las GPUs NVIDIA® permiten a los investigadores de Cryo-EM aprovechar la potencia de las GPUs no sólo para acelerar las tareas de refinamiento y clasificación, sino también para reducir aún más la carga computacional gracias a la elevada densidad de cálculo de las GPUs.
Nuestro objetivo es el de proporcionar al sector de Investigación en Biología una solución de computación intensiva y por consiguiente el facilitar a los investigadores recursos para los procesos de Cryo-EM que son intensivos desde el punto de vista computacional, como la clasificación de imágenes y el refinamiento de alta resolución..
W64 Molecular Dynamics
Ofrecemos un superordenador de Dinámica Molecular en formato desktop. Estación de trabajo de dinámica molecular «plug and play» con las últimas GPU NVIDIA® RTX™, preinstaladas con la pila de software de dinámica molecular.
Hoy en día, aplicaciones de simulación de dinámica molecular como AMBER, GROMACS, NAMD y LAMMPS, entre otras, requieren de GPUs potentes. Cuanto más potente sea la estación de trabajo de la GPU, más rápido se ejecutarán las simulaciones más largas en menos tiempo.
W45 Data Science
W45 Data Science, un sistema que le ofrece el rendimiento que necesita para transformar grandes cantidades de datos en información y crear experiencias de cliente sorprendentes, potenciadas por NVIDIA® para la ciencia de datos. Construida para combinar la potencia de las GPU NVIDIA® RTX™ con el software acelerado de ciencia de datosCUDA-X AI, ofreciendo así una nueva generación de estaciones de trabajo totalmente integradas para la ciencia de datos.
Hoy en día, la ciencia de datos y el aprendizaje automático se han convertido en el segmento informático más grande del mundo. Modestas mejoras en la precisión de los modelos de análisis se convierten en miles de millones en el balance final. Para crear los mejores modelos, los científicos de datos se esfuerzan en entrenar, evaluar, iterar y reentrenar a fin de ofrecer modelos de rendimiento y resultados de alta precisión. ConRAPIDS™, los procesos que tardaban días tardan minutos, lo que facilita y acelera la creación e implementación de modelos de generación de valores.
RAPIDSes un paquete de bibliotecas de software de código abierto e interfaces API para ejecutar canalizaciones de ciencia de datos por completo en las GPU, que puede reducir los tiempos de entrenamiento de días a minutos. Basado enNVIDIA® CUDA-X AI™,RAPIDSconjuga años de desarrollo en gráficos, aprendizaje automático, deep learning, computación de alto rendimiento (HPC) y mucho más.
W45 Data Science, configurada para garantizar el máximo nivel de compatibilidad, capacidad y fiabilidad. Obtenga hasta 96GB de memoria gráfica local ultrarrápida para manejar los conjuntos de datos más grandes y las cargas de trabajo más intensas. Aproveche lo último en tecnología de trazado de rayos para una visualización local de alto rendimiento y configure el acceso remoto para obtener la máxima flexibilidad. Con NVIDIA® RTX™ puede maximizar la productividad, reducir el tiempo de conocimiento y el coste de los proyectos científicos.
W45 Data Science es una estación única para cualquier profesional, una plataforma común para HPC, Inteligencia Artificial, Simulación, Visualización y Análisis en una sola supercomputadora.
Adán Martín [Fundador y Director de 3D Collective SL]: «Para mí es muy importante contar con una maquina actualizada que me permita realizar mi trabajo con comodidad y eficiencia, por esta razón suelo actualizar mi hardware una vez cada 2 años para tratar de contar siempre con las mejores herramientas disponibles.
A principios de 2018 hice una review de la que se convertiría en mi maquina de trabajo por 2 años, un AMD threadripper 1950X. Era mi primera experiencia con AMD en muchos años y no estaba muy seguro de que el nuevo micro de AMD fuera a cumplir con las expectativas, pero el 1950X me demostró que las cosas habían cambiado y he estado muy satisfecho con mi compra desde entonces.
Pero ahora toca actualizar nuevamente equipos y tenia grandes dudas entre los nuevos AMD Threadripper 3990X y 3970X ¿Merecería la pena apostar por el 3990X a pesar de elevado coste?. ¿Seria mejor optar por una maquina con una velocidad base más alta como el 3970X?.
Al final me decidí por el 3970X pero poco después Azken Muga me ha prestado una de sus Workstations W64 con un 3990X para que pueda probarla y me ha parecido que puede ser interesante para vosotros ver como rinde este monstruo en tareas de render comparado con el 3970X. Las dos maquinas han sido montadas por Azken y tienen componentes equiparables en cuanto a placa base, memorias, sistema de refrigeración, etc. así que creo que podemos hacer una comparativa más o menos justa.
Antes de comenzar, deciros que esto no pretende ser un análisis exhaustivo de las maquinas porque no soy un experto en hardware, yo me dedico al 3D como todos sabéis y simplemente he probado las maquinas en las tareas que suelen ocupar mi día a día y he sacado mis conclusiones. Os tocará a vosotros sacar las vuestras.»
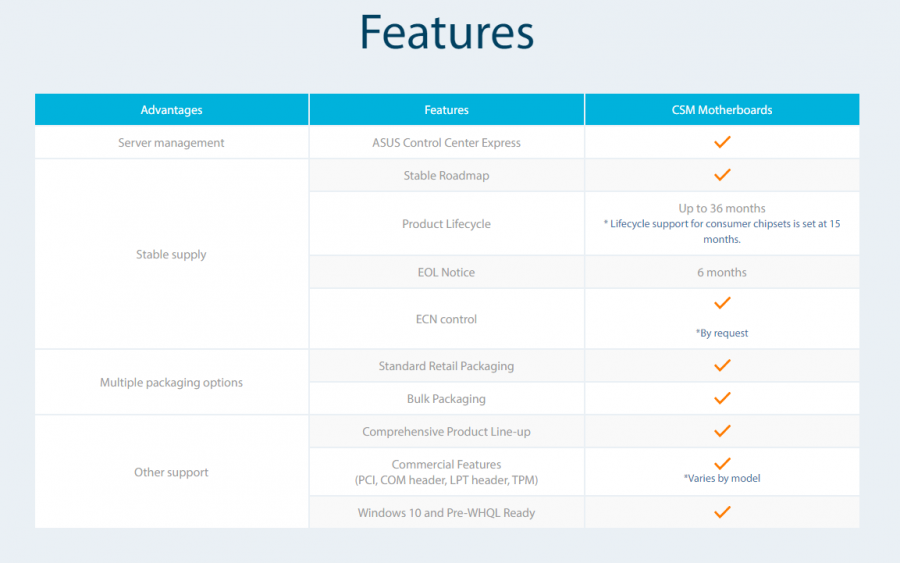
En este artículo queremos hacer una review de dos productos realmente interesantes de Asus. En primer lugar, un software de gestión centralizada de IT para entornos datacenter, enterprise y PYME llamado ASUS Control Center y, por otro lado, la gama de placas base pertenecientes al programa CSM.
En nuestro entorno de pruebas y por gentileza de Asus hemos utilizado las placas base CSM modelos Asus PRO H310M-R R2.0WI-FI/CSM y Asus PRO A320M-RWI-FI/CSM. Estas placas son especialmente adecuadas para nuestro artículo ya que incluye una licencia de uso para ACC edición CSM.
Los productos pertenecientes al programa CSM están pensados para entornos empresariales y entre otras ventajas sobre la gama de productos de consumo, ofrecen un ciclo de vida de 36 meses, la máxima disponibilidad y notificación de cambios. Como nota adicional, Asus asegura que lleva en marcha más de 16 años en otros países con gran éxito.
En el caso del modelo Asus PRO H310M-R R2.0WI-FI/CSM, es una placa basada en un chipset H310 de Intel con soporte para procesadores hasta i7 de 8ª generación con gráficos integrados, en un formato Micro-ATX, con conectividad PCIe 3.0, Ethernet 1Gbit, Wifi Dual band integrado y Bluetooth 5.0. También incluye audio y soporte hasta 32GB de memoria DDR4.
En el caso de la placa Asus PRO A320M-RWI-FI/CSM, está basada en un chipset AMD 320 y socket AM4 con soporte para procesadores Ryzen de 3ª generación hasta 8 cores y gráficos integrados Radeon Vega. Igual que la anterior en un formato Micro-ATX, con conectividad PCIe 3.0, Ethernet 1Gbit, Wifi Dual band integrado y Bluetooth 5.0. También incluye audio y soporte hasta 32GB de memoria DDR4.
Pero lo que realmente diferencia a estos productos es que están especialmente dirigidas al sector profesional, a entornos IT empresarial y gama Enterprise. Por ejemplo, incluyen mecanismos de fiabilidad 24/7, recuperación automática de BIOS, registro de errores en BIOS, una construcción especialmente sólida anti-humedad y corrosión. También disponen de garantía de disponibilidad a largo plazo y soporte postventa mejorado.
Asus Control Center
Asus Control Center o ACC es una plataforma de gestión centralizada para entornos de IT que permite la gestión y monitorización de servidores Asus, estaciones de trabajo y productos de gama consumer como portátiles, equipos de sobremesa, Pc´s All-in-one y cartelería digital.
El producto está diseñado para ser especialmente intuitivo y fácil de usar, y entre otras funciones permite el deployment de aplicaciones remotas, programar tareas de mantenimiento, monitorización hardware y software, y muchas más funciones imprescindibles para una gestión eficiente del entorno IT y datacenter. Algo muy interesante es que no sólo funciona con máquinas físicas, sino también con máquinas virtuales siendo compatible con Hypervisors como VMWare. Todo por supuesto gestionado de manera segura. En el momento de escribir este artículo existen 3 versiones de ACC, Classic, CSM y Enterprise, adaptados a las necesidades y tamaño de cualquier organización.
El funcionamiento de ACC está basada en unos agentes que se instalan y se ejecutan en los equipos que queremos gestionar. Estos agentes recolectan y registran información que podemos visualizar a través de una consola de gestión basada en web.
Para empezar lo primero que hay que hacer es poner en marcha ACC. Este primer paso es extraordinariamente sencillo y fácil, ya que ACC está basado en una máquina virtual VM Linux compatible con VMware, Hyper-V y Oracle VirtualBox que Asus suministra a través de una imagen OVA y que se puede poner en marcha en cualquier equipo que cumpla los requisitos mínimos de 4vCPU, 8GB de memoria RAM, 100GB de HD.
En nuestras pruebas decidimos usar Virtual Box por la inmediatez, facilidad de instalación y uso en cualquier equipo con Windows o Linux. Hemos seguido la documentación de Asus ACC, la cual está perfectamente detallada y funciona correctamente para instalar Oracle Virtual Box y poner en marcha ACC.
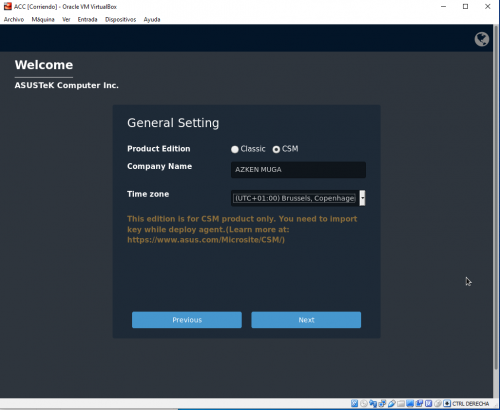
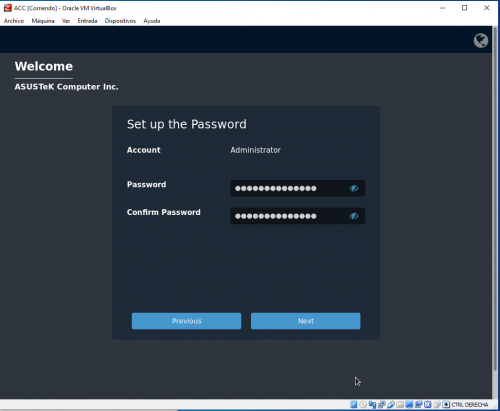
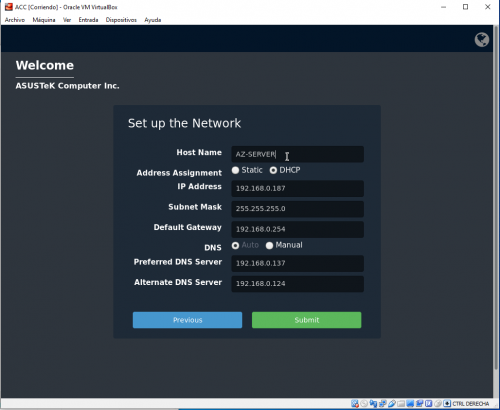
Una vez completado el setup inicial de la VM y el arranque, se ejecuta un asistente que nos permitirá realizar la configuración inicial básica, incluyendo datos como el nombre de la compañía, zona horaria, passwords de acceso y direcciones IP, tal y como vemos en las siguientes pantallas:
A partir de este momento ya somos capaces de acceder a ACC mediante cualquier navegador de internet y que nos permitirá acceder a todas las funciones de Asus ACC. Para acceder escribimos en la barra de direcciones del navegador la dirección IP o hostname con el siguiente formato, en nuestro caso:
Ojo que las mayúsculas de “ACC” son importantes.
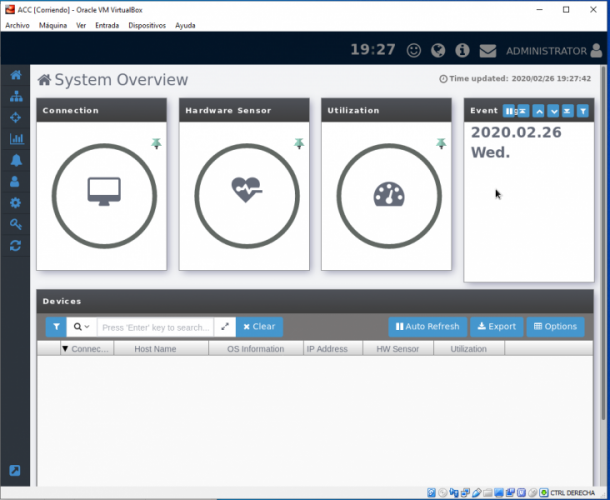
Como último paso antes de acceder a ACC, nos solicitará un usuario y un password. Una vez dentro visualizaremos una pantalla similar a esta, que es un resumen del sistema que estemos monitorizando:
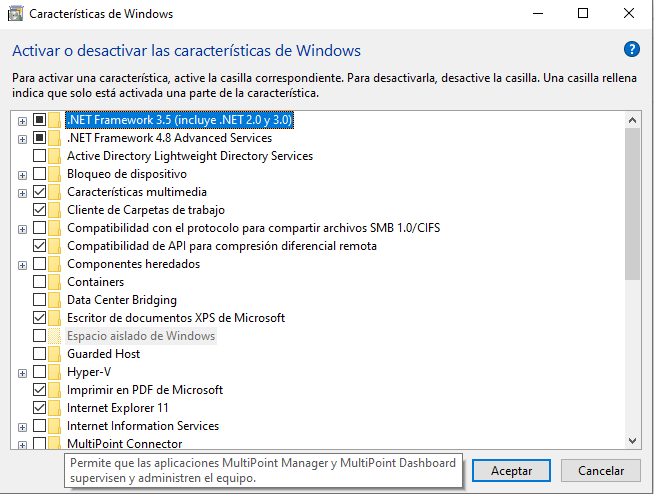
En este momento no veremos datos útiles, esto es normal ya que no hay sistemas que monitorizar, los cuales debemos ir añadiendo. Antes de añadir sistemas a ACC, es necesario prepararlos activando ciertas configuraciones de software muy sencillas como activar .NET framework 3.5 y algunos settings de compartición de ficheros e impresoras. Hay que tener en cuenta que ACC NO es compatible con sistemas Windows Home Edition o inferiores.
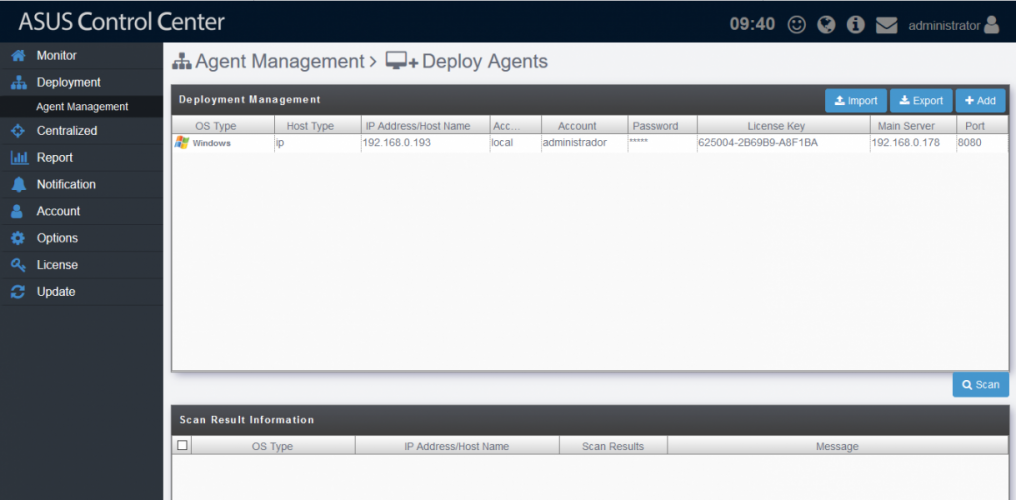
A continuación, podremos añadir equipos desde la pestaña “Deployment” y “Add”, seguimos los pasos y nuestros sistemas irán apareciendo en la consola, también podemos añadir muchos sistemas de una vez lo cual facilita enormemente los grandes deployments.
Como hemos dicho anteriormente, una parte muy interesante es la posibilidad de integrarlo en infraestructuras virtualizadas vía VMWare, esto lo podemos hacer desde la opción “Agentless Management”, aunque para tener disponible esta opción es necesario disponer de una licencia “Enterprise”.
A partir de este momento tendremos acceso a toda la potencia y versatilidad de la solución, algunos ejemplos:
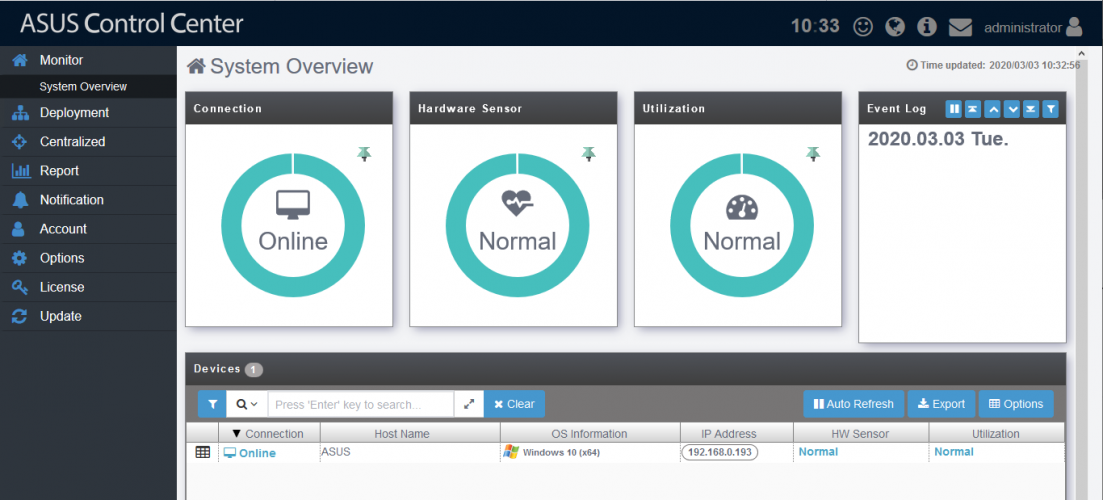
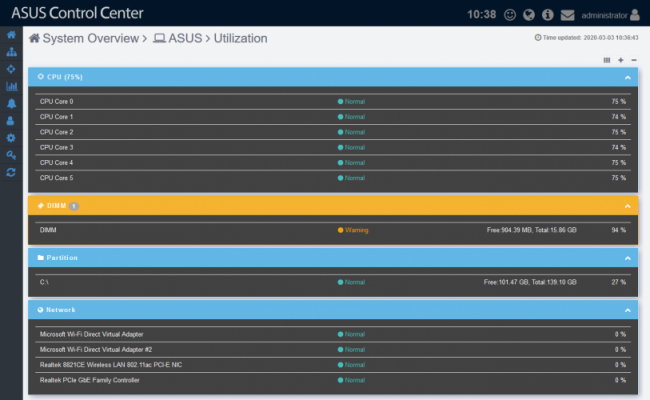
Overview general de una máquina:
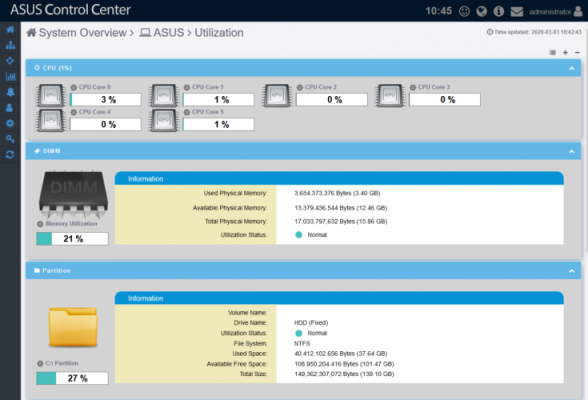
Información del estado de uso del hardware de manera gráfica e intuitiva:
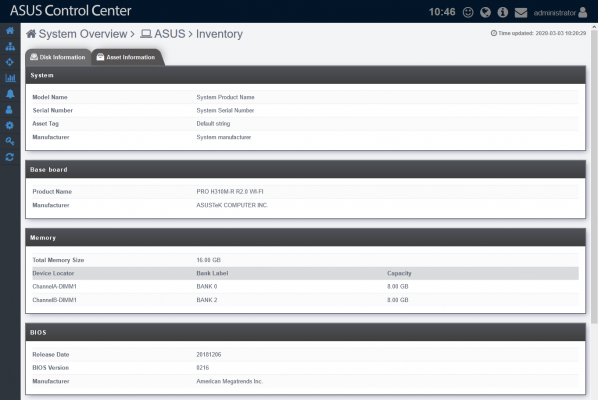
Gestión de inventario:
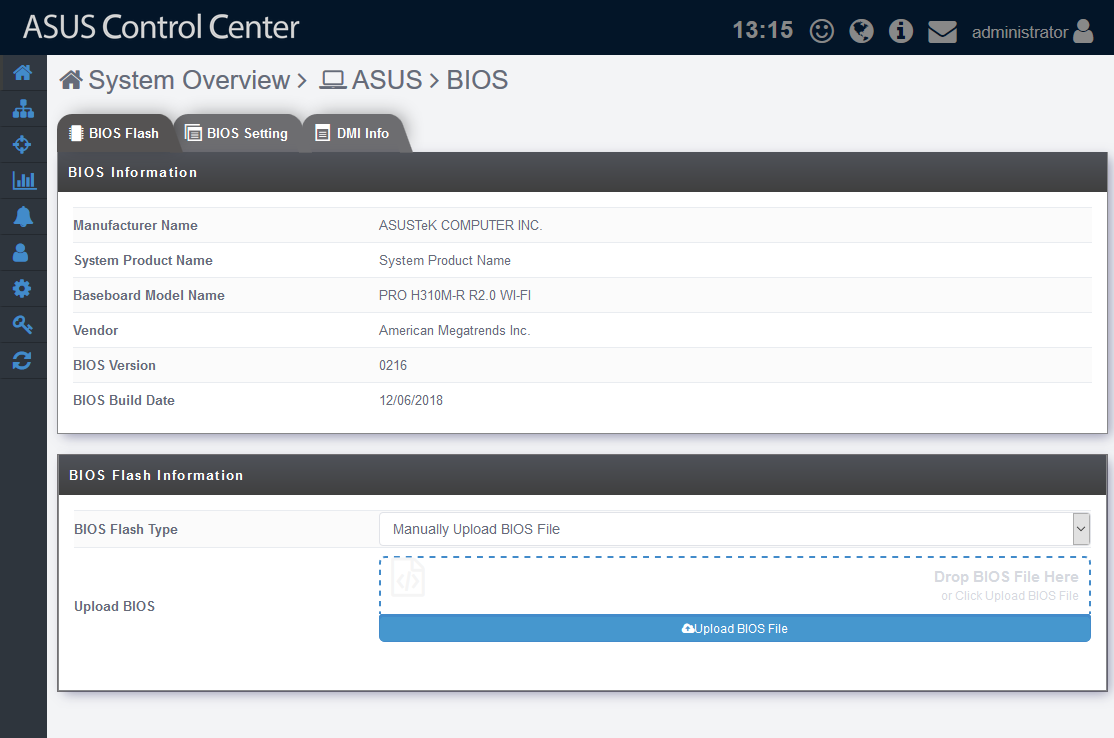
Actualización de BIOS:
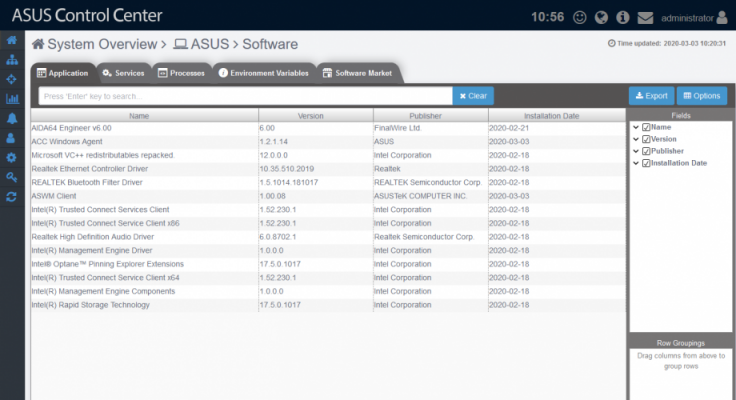
Gestión de software y servicios:
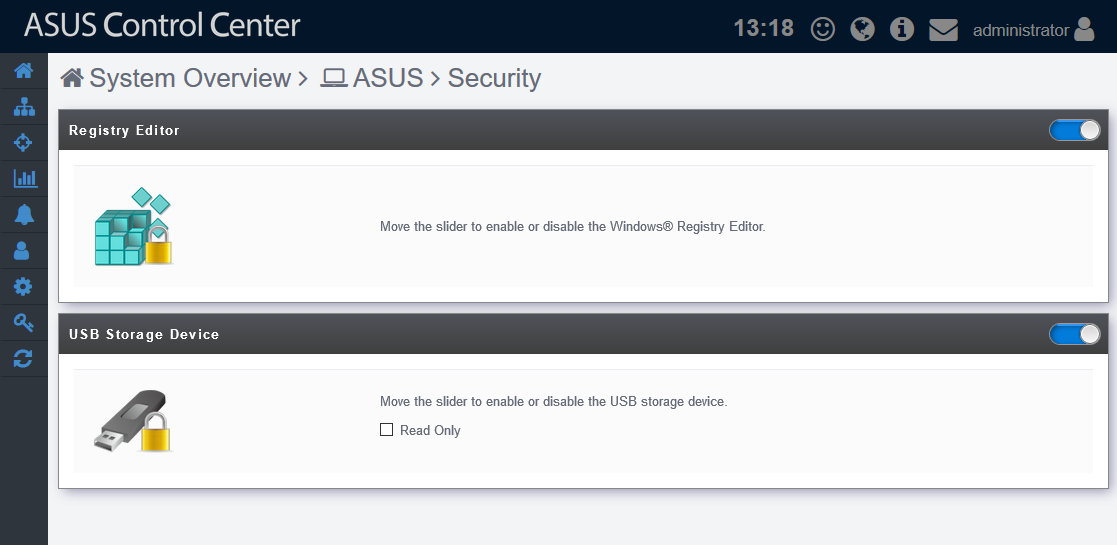
Funciones de seguridad como impedir el uso de USB o modificación del registro:
Y muchas más funciones necesarias para la gestión eficaz de infraestructura de IT.
Adicionalmente algunas posibilidades que lo hacen extremadamente atractivo por ejemplo para Datacenters es la integración con Intel Datacenter manager, que permite gestionar y programar el consumo de la infraestructura.