NVIDIA T4 lleva aceleración por GPU a los servidores empresariales líderes en el mundo.
Las GPUs profesionales NVIDIA T4 y las librerías de aceleración CUDA-X preparan los Data Center para las diversas y complejas cargas de trabajo actuales que incluyen HPC Deep Learning tanto entrenamiento como inferencia, machine learning, data analytics, encoding y visualización gráfica. Con el soporte de la plataforma NGC (Nvidia GPU Cloud), los equipos de TI pueden construir infraestructuras de Data Center acelerados por GPU estándar con la mayoría de los fabricantes de servidores del mundo como ASUS Server.
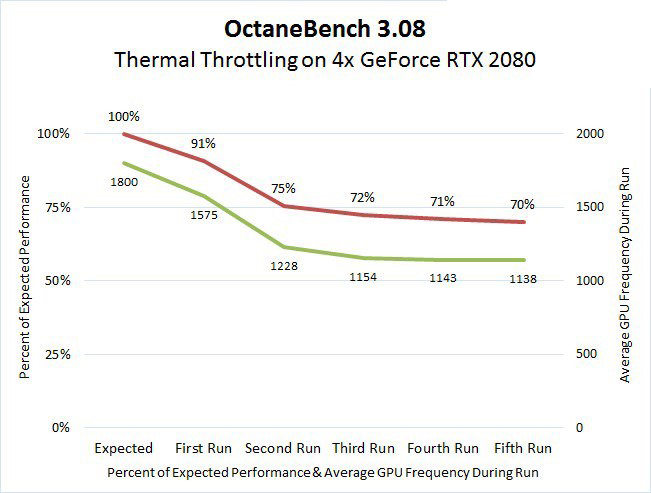
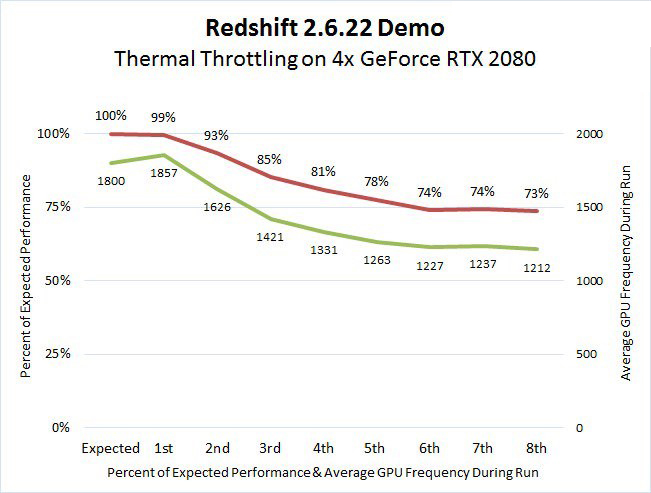
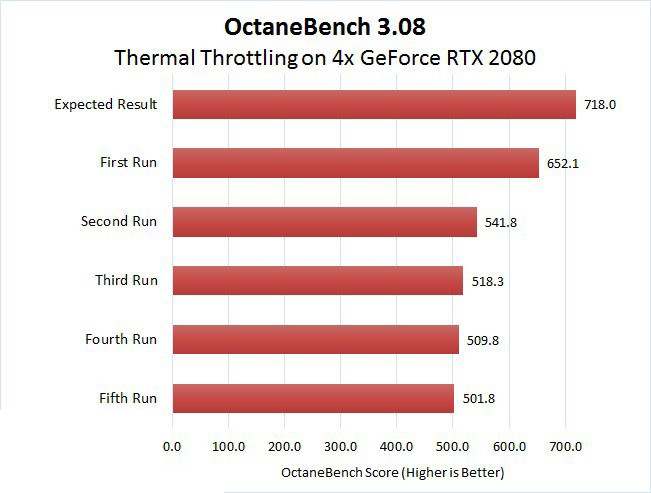
Con respecto a la configuraciones clásica de CPU (Ver: Nota al pie) con NVIDIA T4 obtenemos:
- Hasta un 33% más de rendimiento en infraestructuras de escritorio virtual (VDI).
- Hasta 35x veces más rápido en Machine Learning.
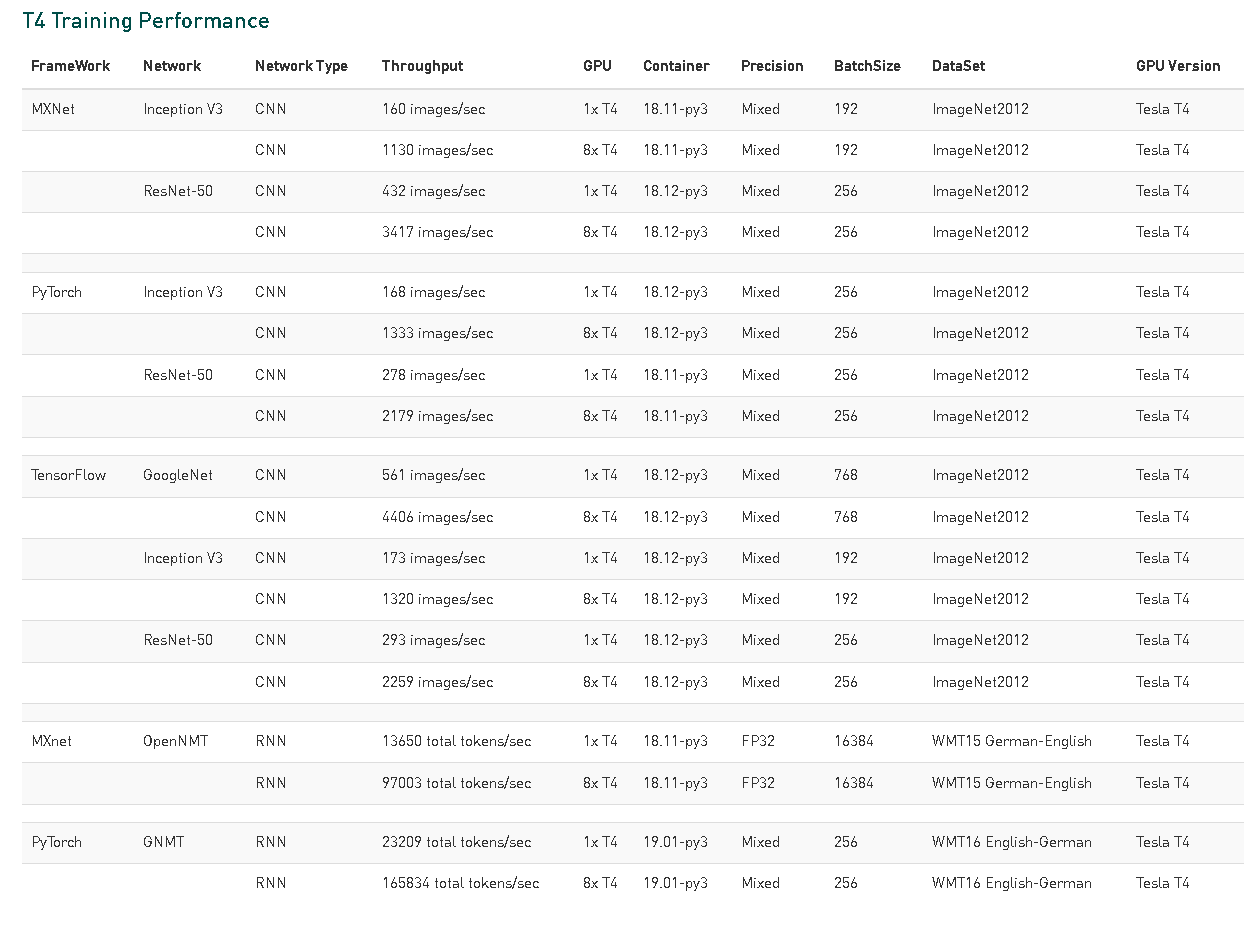
- Hasta 10 veces más rápido en entrenamiento en Deep Learning.
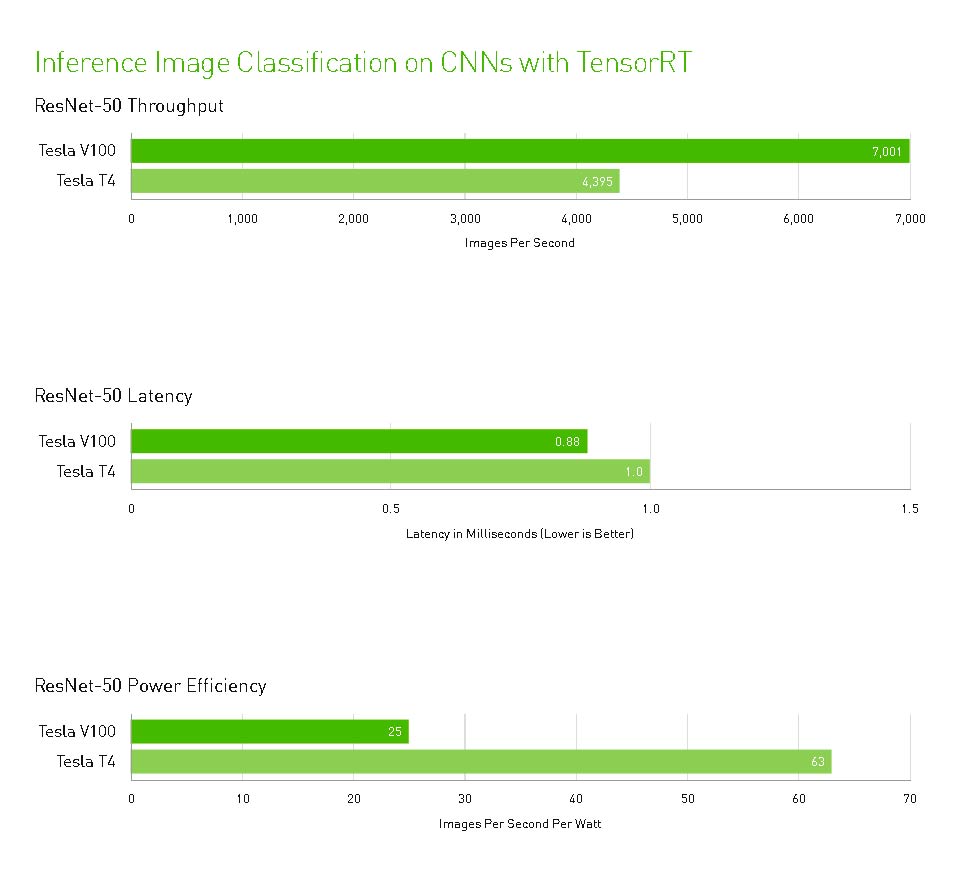
- Hasta 40 veces más rápido para obtener información sobre la inferencia de Deep Learning.
(Nota el pie de pagina)
Aceleración en Deep Learning
Si bien el Deep Learning ha llegado bastante recientemente al mercado de la IA, las compañías han estado utilizando el Deep Learning para recopilar información a partir de datos durante décadas. La GPU del centro de datos NVIDIA T4 puede acelerar estas técnicas de aprendizaje automático utilizando RAPIDS, un conjunto de bibliotecas de open source para la preparación de datos y Deep Learning en la GPU. Usando herramientas de desarrollo familiares como Python, una GPU T4 puede acelerar el aprendizaje de la máquina hasta 35X en comparación con un servidor solo para CPU, incluidos algoritmos como XGBoost, PCA, K-means, k-NN, DBScan y tSVD.
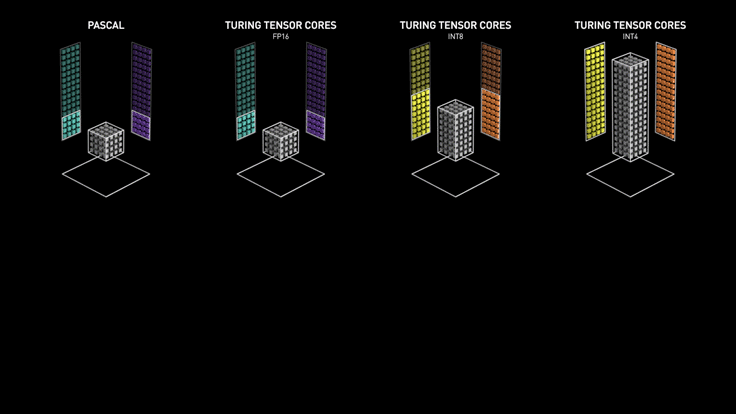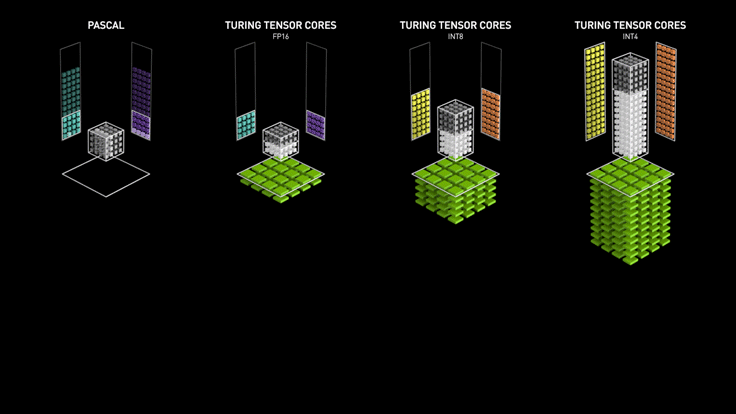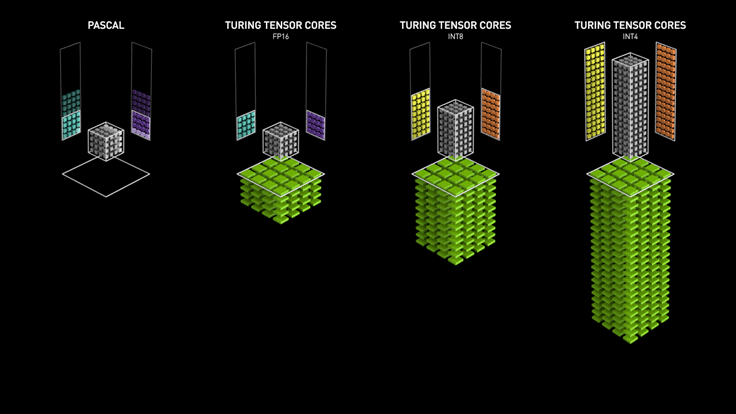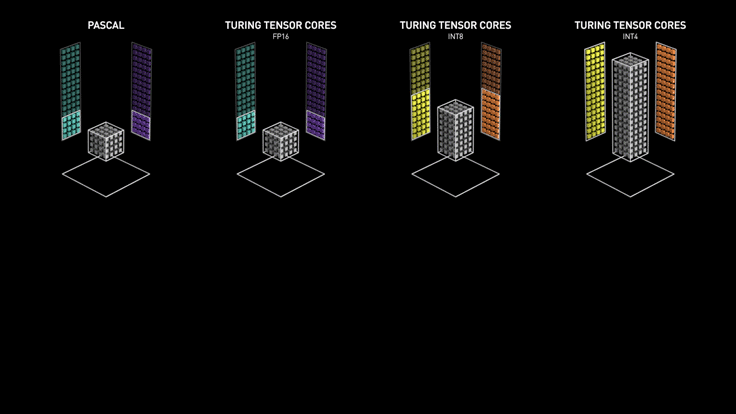
Los Tensor cores de Turing aceleran NVIDIA T4 en servidores profesionales.
NVIDIA T4 se basa en la revolucionaria tecnología Tensor Core de NVIDIA Turing ™ con computación de precisión múltiple para Workloads de AI. Al potenciar el rendimiento innovador de FP32 y FP16 a INT8, así como a INT4, T4 ofrece un rendimiento de inferencia hasta 40 veces mayor que las CPU, para capacitación, un solo servidor con dos GPU T4 reemplaza nueve servidores de CPU de doble socket.
Los desarrolladores pueden utilizar los Tensor Core de Turing directamente a través de las bibliotecas de software NVIDIA CUDA-X AI integrándose con todos los frameworks de AI. Construidas sobre CUDA, el modelo de programación paralelo de NVIDIA, las librerías CUDA-X proporcionan optimizaciones para los requisitos informáticos específicos de inteligencia artificial, máquinas autónomas, computación de alto rendimiento y gráficos.