NVIDIA GH200 NVL32
AWS será el primer proveedor de cloud computing en ofrecer los superchips NVIDIA GH200 Grace Hopper. Interconectados con la tecnología NVIDIA NVLink a través de NVIDIA DGX Cloud se ejecutarán en Amazon Elastic Compute Cloud (Amazon EC2).
Se trata de una tecnología revolucionaria para la computación en la nube.

NVIDIA GH200 NVL32 es una solución de rack escalable dentro de NVIDIA DGX Cloud o en las infraestructuras de Amazon. Cuenta con un dominio NVIDIA NVLink de 32 GPU y una enorme memoria unificada de 19,5 TB. Superando las limitaciones de memoria de un único sistema, es 1,7 veces más rápida para el entrenamiento GPT-3 y 2 veces más rápida para la inferencia de modelos de lenguaje de gran tamaño (LLM) en comparación con NVIDIA HGX H100.
Las infraestructuras de AWS equipadas con NVIDIA GH200 Grace Hopper Superchip contarán con 4,5 TB de memoria HBM3e. Esto supone un aumento de 7,2 veces en comparación con las EC2 P5 equipadas con NVIDIA H100. Esto permite a los desarrolladores ejecutar modelos de mayor tamaño y mejorar el rendimiento del entrenamiento.
Además, la interconexión de memoria de la CPU a la GPU es de 900 GB/s, 7 veces más rápida que PCIe Gen 5. Las GPU acceden a la memoria de la CPU de forma coherente con la caché, lo que amplía la memoria total disponible para las aplicaciones. Este es el primer uso del diseño escalable GH200 NVL32 de NVIDIA. Un diseño de referencia modular para supercomputación, centros de datos e infraestructuras en la nube. Proporciona una arquitectura común para las configuraciones de procesadores GH200 y sucesores.
En este artículo se explica la infraestructura que lo hace posible y se incluyen algunas aplicaciones representativas.
NVIDIA GH200 NVL32
NVIDIA GH200 NVL32 es un modelo de rack para los superchips NVIDIA GH200 Grace Hopper conectados a través de NVLink destinado a centros de datos de hiperescala. Admite 16 nodos de servidor Grace Hopper duales compatibles con el diseño de chasis NVIDIA MGX. Admite refrigeración líquida para maximizar la densidad y la eficiencia del cálculo.
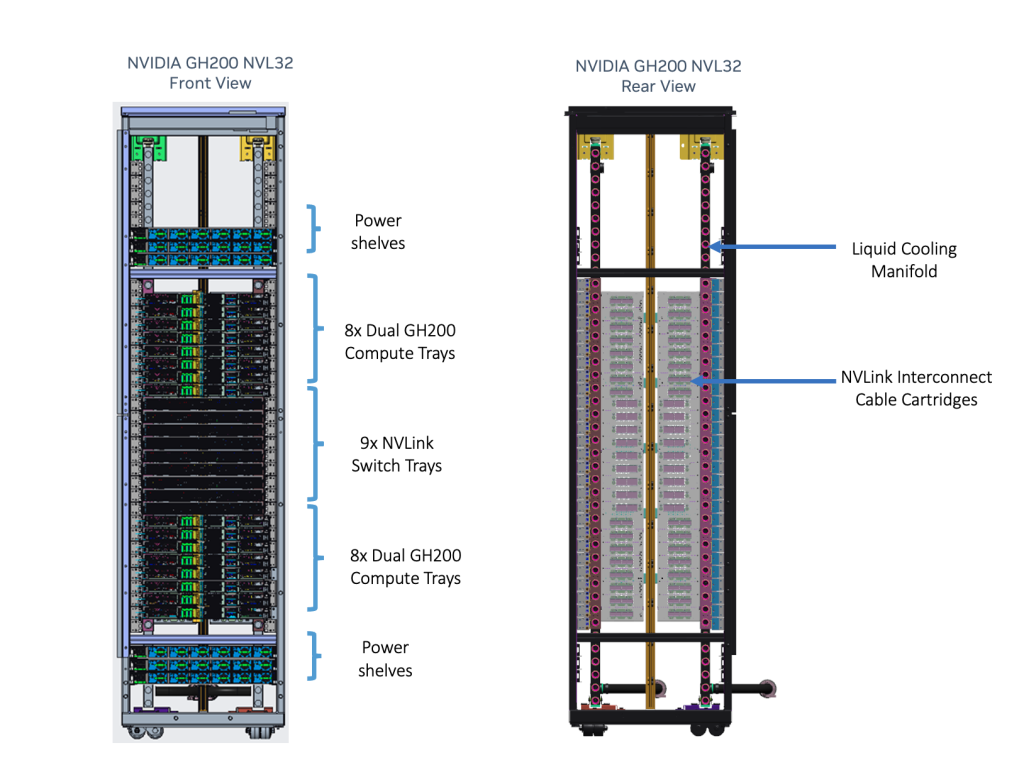
NVIDIA GH200 Grace Hopper Superchip con un NVLink-C2C coherente crea un espacio de direcciones de memoria direccionable NVLink para simplificar la programación de modelos. Combina memoria de sistema de gran ancho de banda y bajo consumo, LPDDR5X y HBM3e, para aprovechar al máximo la aceleración de la GPU NVIDIA y los núcleos Arm de alto rendimiento en un sistema bien equilibrado.
Los nodos del servidor GH200 están conectados con un cartucho de cable de cobre pasivo NVLink para permitir que cada GPU Hopper acceda a la memoria de cualquier otro Superchip Grace Hopper de la red. Lo que proporciona 32 x 624 GB, o 19,5 TB de memoria direccionable NVLink.
Esta actualización del sistema de conmutación NVLink utiliza la interconexión de cobre NVLink para conectar 32 GPU GH200 mediante nueve conmutadores NVLink que incorporan chips NVSwitch de tercera generación. El sistema de conmutación NVLink implementa una red fat-tree totalmente conectada para todas las GPU del cluster. Para necesidades de mayor escala, el escalado con InfiniBand o Ethernet a 400 Gb/s proporciona un rendimiento increíble y una solución de supercomputación de IA de bajo consumo energético.
NVIDIA GH200 NVL32 es compatible con el SDK HPC de NVIDIA y el conjunto completo de librerías CUDA, NVIDIA CUDA-X y NVIDIA Magnum IO. Lo que permite acelerar más de 3.000 aplicaciones de GPU.
Casos de uso y resultados de rendimiento
NVIDIA GH200 NVL32 es ideal para el entrenamiento y la inferencia de la IA, los sistemas de recomendación, las redes neuronales de grafos (GNN), las bases de datos vectoriales y los modelos de generación aumentada por recuperación (RAG), como se detalla a continuación.
Entrenamiento e inferencia de IA
La IA generativa ha irrumpido con fuerza en todo el mundo, como demuestran las revolucionarias capacidades de servicios como ChatGPT. LLMs como GPT-3 y GPT-4 están permitiendo la integración de capacidades de IA en todos los productos de todas las industrias, y su tasa de adopción es asombrosa.
ChatGPT se convirtió en la aplicación que más rápido alcanzó los 100 millones de usuarios, logrando ese hito en sólo 2 meses. La demanda de aplicaciones de IA generativa es inmensa y crece exponencialmente.
Los LLM requieren un entrenamiento a gran escala y multi-GPU. Los requisitos de memoria para GPT-175B serían de 700 GB, ya que cada parámetro necesita cuatro bytes (FP32). Se utiliza una combinación de paralelismo de modelos y comunicaciones rápidas para evitar quedarse sin memoria con GPU de memoria más pequeña.
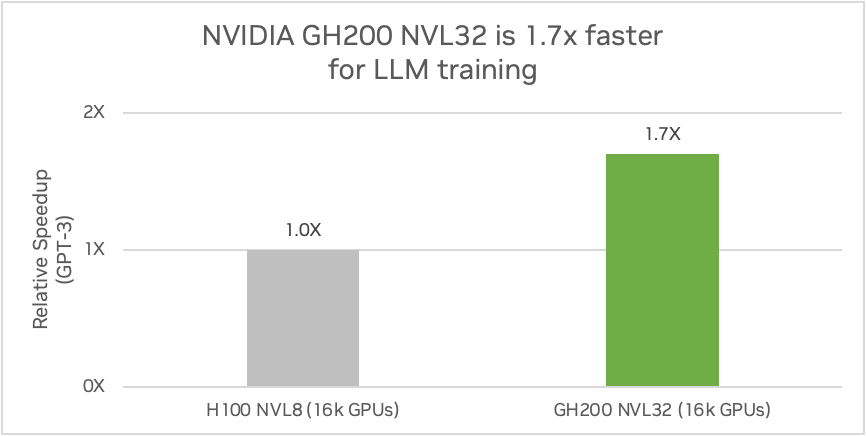
NVIDIA GH200 NVL32 está diseñada para la inferencia y el entrenamiento de la próxima generación de LLM. Al superar los cuellos de botella de memoria, comunicaciones y cálculo con 32 superchips Grace Hopper GH200 conectados por NVLink, el sistema puede entrenar un modelo de un billón de parámetros 1,7 veces más rápido que NVIDIA HGX H100.
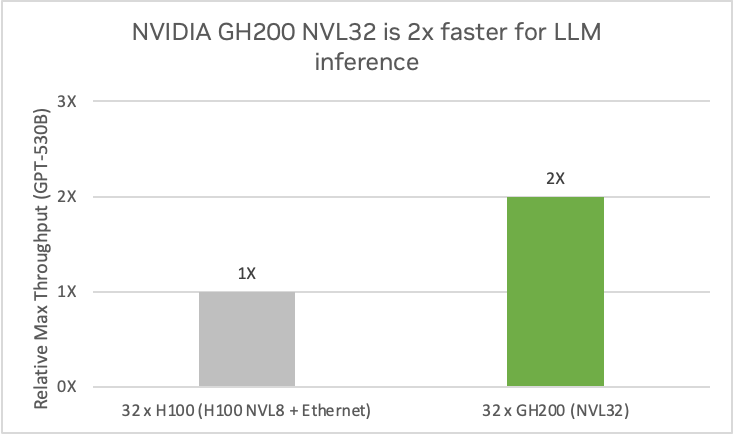
El sistema NVIDIA GH200 NVL32 multiplica por 2 el rendimiento de cuatro sistemas H100 NVL8 con un modelo de inferencia GPT-530B. El gran espacio de memoria también mejora la eficiencia operativa, ya que permite almacenar varios modelos en el mismo nodo e intercambiarlos rápidamente para maximizar su utilización.
Sistemas de recomendación
Los sistemas de recomendación son el motor del Internet personalizado. Se utilizan en comercio electrónico y minorista, medios de comunicación y redes sociales, anuncios digitales, etc. para personalizar contenidos. Esto genera ingresos y valor empresarial. Los recomendadores utilizan incrustaciones que representan a los usuarios, los productos, las categorías y el contexto, y pueden tener un tamaño de hasta decenas de terabytes.
Un sistema de recomendación muy preciso proporcionará una experiencia de usuario más atractiva, pero también requiere una incrustación mayor. Las incrustaciones tienen características únicas para los modelos de IA, ya que requieren grandes cantidades de memoria con un gran ancho de banda y una conexión en red ultrarrápida.
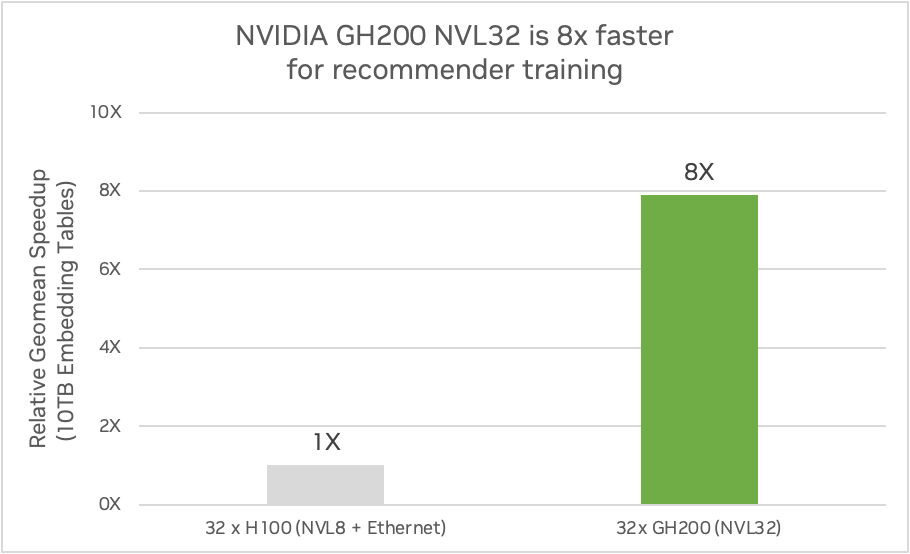
NVIDIA GH200 NVL32 con Grace Hopper proporciona 7 veces más cantidad de memoria de acceso rápido en comparación con cuatro HGX H100 y proporciona 7 veces más ancho de banda en comparación con las conexiones PCIe Gen5 a la GPU en diseños convencionales basados en x86. Permite incrustaciones 7 veces más detalladas en comparación con las H100 con x86.
También puede proporcionar hasta 7,9 veces más rendimiento de entrenamiento para modelos con tablas de incrustación masivas. La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando un modelo DLRM. Las comparaciones se realizaron entre los sistemas GH200 y H100 utilizando tablas de incrustación de 10 TB y utilizando tablas de incrustación de 2 TB.
Redes neuronales gráficas
Las GNN (Graph Neural Networks) aplican el poder predictivo del aprendizaje profundo a ricas estructuras de datos que representan objetos y sus relaciones como puntos conectados por líneas en un gráfico. Muchas ramas de la ciencia y la industria ya almacenan datos valiosos en bases de datos de gráficos.
El aprendizaje profundo se utiliza para entrenar modelos predictivos que descubren nuevas perspectivas a partir de gráficos. Cada vez son más las organizaciones que aplican las GNN para mejorar el descubrimiento de fármacos, la detección de fraudes, la infografía, la ciberseguridad, la genómica, la ciencia de los materiales y los sistemas de recomendación. En la actualidad, los gráficos más complejos procesados por GNN tienen miles de millones de nodos, billones de aristas y funciones repartidas entre nodos y aristas.
NVIDIA GH200 NVL32 proporciona memoria masiva de CPU-GPU para almacenar estas complejas estructuras de datos y acelerar el cálculo. Además, los algoritmos de gráficos a menudo requieren accesos aleatorios a estos grandes conjuntos de datos que almacenan las propiedades de los vértices.
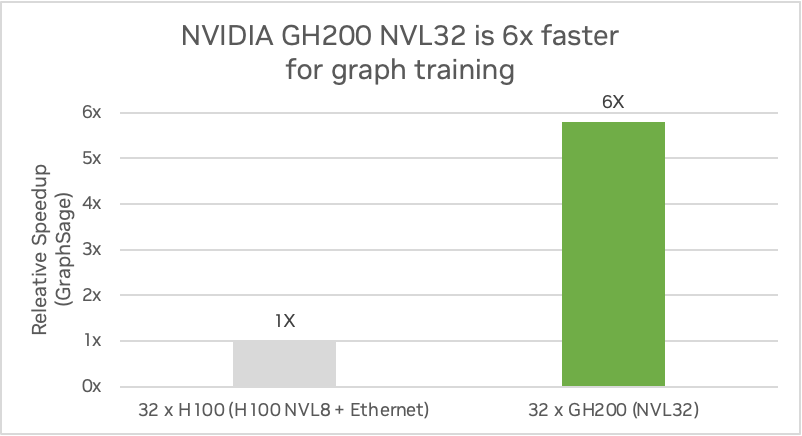
Estos accesos suelen verse limitados por el ancho de banda de las comunicaciones entre nodos. La conectividad GPU-GPU NVLink de NVIDIA GH200 NVL32 proporciona una enorme aceleración de estos accesos aleatorios. GH200 NVL32 puede aumentar el rendimiento de entrenamiento de GNN hasta 5,8 veces en comparación con NVIDIA H100.
La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando GraphSAGE. GraphSAGE es un marco inductivo general para generar de forma eficiente incrustaciones de nodos para datos no vistos previamente.
Resumen
Amazon y NVIDIA han anunciado la llegada de NVIDIA DGX Cloud a AWS. AWS será el primer proveedor de servicios en la nube en ofrecer NVIDIA GH200 NVL32 en DGX Cloud y como instancia EC2. La solución NVIDIA GH200 NVL32 cuenta con un dominio NVLink de 32 GPU y 19,5 TB de memoria unificada. Esta configuración supera con creces a los modelos anteriores en el entrenamiento GPT-3 y la inferencia LLM.
La interconexión de memoria CPU-GPU de la NVIDIA GH200 NVL32 es extraordinariamente rápida, lo que mejora la disponibilidad de memoria para las aplicaciones. Esta tecnología forma parte de un modelo escalable para centros de datos de hiperescala, respaldado por un completo paquete de software y librerías de NVIDIA, que acelera miles de aplicaciones de GPU. NVIDIA GH200 NVL32 es ideal para tareas como el entrenamiento y la inferencia de LLM, los sistemas de recomendación y las GNN, entre otras, ya que ofrece mejoras significativas del rendimiento de las aplicaciones de IA y computación.
Fuente: NVIDIA

