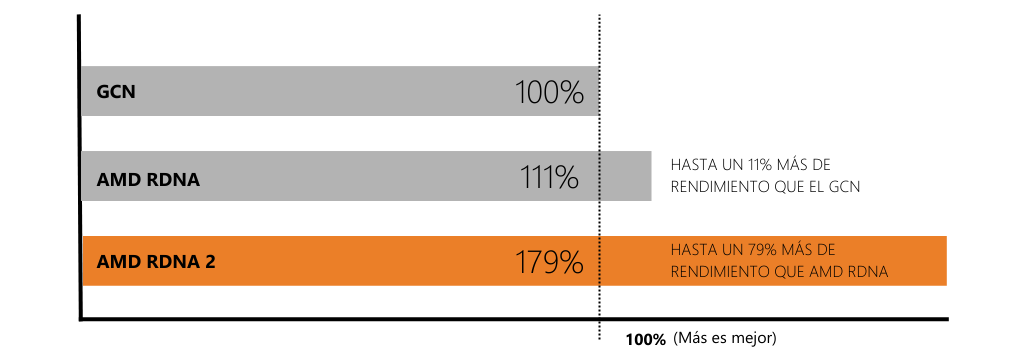AWS será el primer proveedor de cloud computing en ofrecer los superchips NVIDIA GH200 Grace Hopper. Interconectados con la tecnología NVIDIA NVLink a través de NVIDIA DGX Cloud se ejecutarán en Amazon Elastic Compute Cloud (Amazon EC2).
Se trata de una tecnología revolucionaria para la computación en la nube.
NVIDIA GH200 NVL32 es una solución de rack escalable dentro de NVIDIA DGX Cloud o en las infraestructuras de Amazon. Cuenta con un dominio NVIDIA NVLink de 32 GPU y una enorme memoria unificada de 19,5 TB. Superando las limitaciones de memoria de un único sistema, es 1,7 veces más rápida para el entrenamiento GPT-3 y 2 veces más rápida para la inferencia de modelos de lenguaje de gran tamaño (LLM) en comparación con NVIDIA HGX H100.
Las infraestructuras de AWS equipadas con NVIDIA GH200 Grace Hopper Superchip contarán con 4,5 TB de memoria HBM3e. Esto supone un aumento de 7,2 veces en comparación con las EC2 P5 equipadas con NVIDIA H100. Esto permite a los desarrolladores ejecutar modelos de mayor tamaño y mejorar el rendimiento del entrenamiento.
Además, la interconexión de memoria de la CPU a la GPU es de 900 GB/s, 7 veces más rápida que PCIe Gen 5. Las GPU acceden a la memoria de la CPU de forma coherente con la caché, lo que amplía la memoria total disponible para las aplicaciones. Este es el primer uso del diseño escalable GH200 NVL32 de NVIDIA. Un diseño de referencia modular para supercomputación, centros de datos e infraestructuras en la nube. Proporciona una arquitectura común para las configuraciones de procesadores GH200 y sucesores.
En este artículo se explica la infraestructura que lo hace posible y se incluyen algunas aplicaciones representativas.
NVIDIA GH200 NVL32
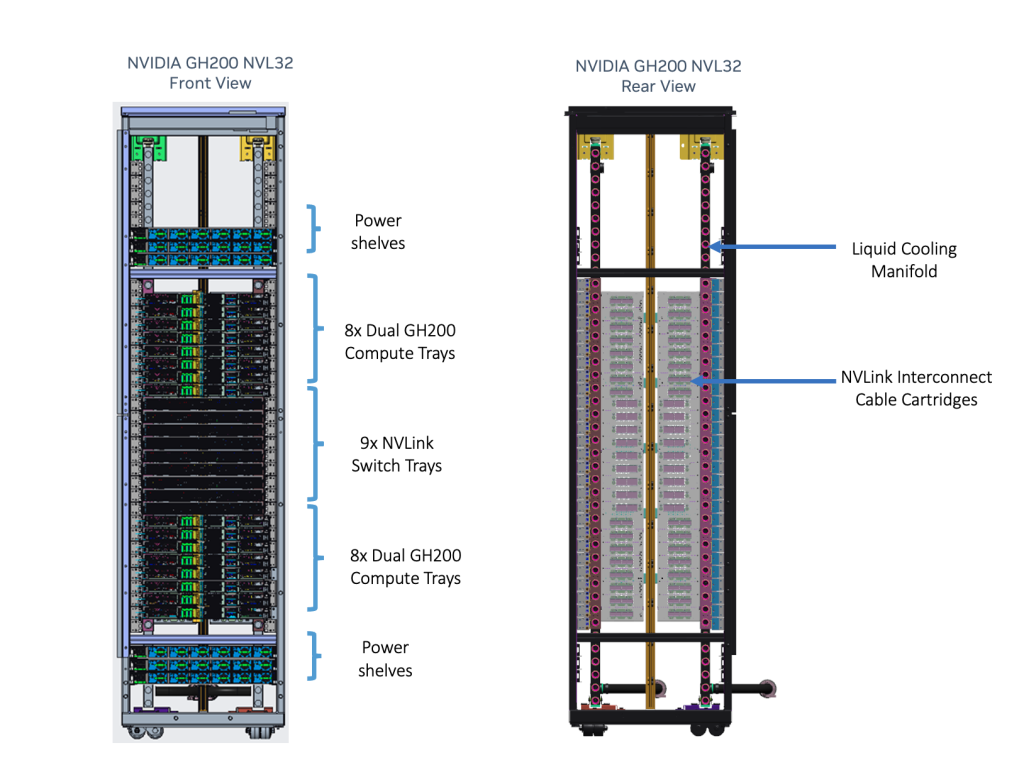
NVIDIA GH200 NVL32 es un modelo de rack para los superchips NVIDIA GH200 Grace Hopper conectados a través de NVLink destinado a centros de datos de hiperescala. Admite 16 nodos de servidor Grace Hopper duales compatibles con el diseño de chasis NVIDIA MGX. Admite refrigeración líquida para maximizar la densidad y la eficiencia del cálculo.
NVIDIA GH200 NVL32 es una solución a escala de rack que ofrece un dominio NVLink de 32 GPU y 19,5 TB de memoria unificada. Fuente: NVIDIA
NVIDIA GH200 Grace Hopper Superchip con un NVLink-C2C coherente crea un espacio de direcciones de memoria direccionable NVLink para simplificar la programación de modelos. Combina memoria de sistema de gran ancho de banda y bajo consumo, LPDDR5X y HBM3e, para aprovechar al máximo la aceleración de la GPU NVIDIA y los núcleos Arm de alto rendimiento en un sistema bien equilibrado.
Los nodos del servidor GH200 están conectados con un cartucho de cable de cobre pasivo NVLink para permitir que cada GPU Hopper acceda a la memoria de cualquier otro Superchip Grace Hopper de la red. Lo que proporciona 32 x 624 GB, o 19,5 TB de memoria direccionable NVLink.
Esta actualización del sistema de conmutación NVLink utiliza la interconexión de cobre NVLink para conectar 32 GPU GH200 mediante nueve conmutadores NVLink que incorporan chips NVSwitch de tercera generación. El sistema de conmutación NVLink implementa una red fat-tree totalmente conectada para todas las GPU del cluster. Para necesidades de mayor escala, el escalado con InfiniBand o Ethernet a 400 Gb/s proporciona un rendimiento increíble y una solución de supercomputación de IA de bajo consumo energético.
NVIDIA GH200 NVL32 es compatible con el SDK HPC de NVIDIA y el conjunto completo de librerías CUDA, NVIDIA CUDA-X y NVIDIA Magnum IO. Lo que permite acelerar más de 3.000 aplicaciones de GPU.
Casos de uso y resultados de rendimiento
NVIDIA GH200 NVL32 es ideal para el entrenamiento y la inferencia de la IA, los sistemas de recomendación, las redes neuronales de grafos (GNN), las bases de datos vectoriales y los modelos de generación aumentada por recuperación (RAG), como se detalla a continuación.
Entrenamiento e inferencia de IA
La IA generativa ha irrumpido con fuerza en todo el mundo, como demuestran las revolucionarias capacidades de servicios como ChatGPT. LLMs como GPT-3 y GPT-4 están permitiendo la integración de capacidades de IA en todos los productos de todas las industrias, y su tasa de adopción es asombrosa.
ChatGPT se convirtió en la aplicación que más rápido alcanzó los 100 millones de usuarios, logrando ese hito en sólo 2 meses. La demanda de aplicaciones de IA generativa es inmensa y crece exponencialmente.
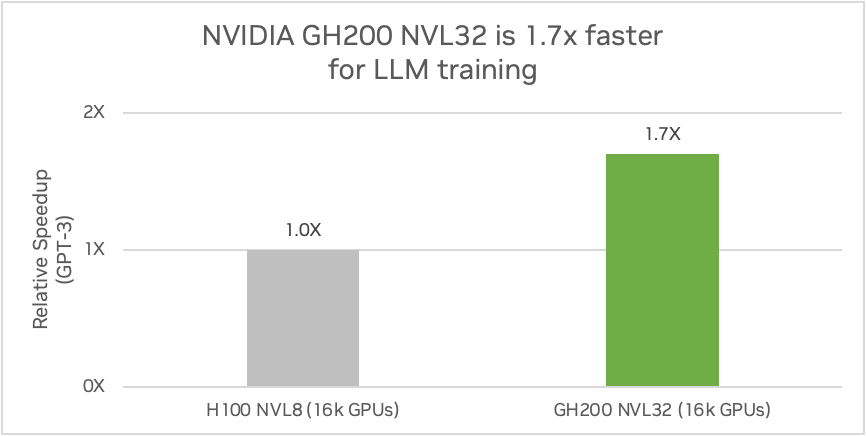
Un centro de datos Ethernet con 16.000 GPUs que utilice NVIDIA GH200 NVL32 ofrecerá 1,7 veces más rendimiento que uno compuesto por H100 NVL8, que es un servidor NVIDIA HGX H100 con ocho GPUs H100 conectadas mediante NVLink. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Los LLM requieren un entrenamiento a gran escala y multi-GPU. Los requisitos de memoria para GPT-175B serían de 700 GB, ya que cada parámetro necesita cuatro bytes (FP32). Se utiliza una combinación de paralelismo de modelos y comunicaciones rápidas para evitar quedarse sin memoria con GPU de memoria más pequeña.
NVIDIA GH200 NVL32 está diseñada para la inferencia y el entrenamiento de la próxima generación de LLM. Al superar los cuellos de botella de memoria, comunicaciones y cálculo con 32 superchips Grace Hopper GH200 conectados por NVLink, el sistema puede entrenar un modelo de un billón de parámetros 1,7 veces más rápido que NVIDIA HGX H100.
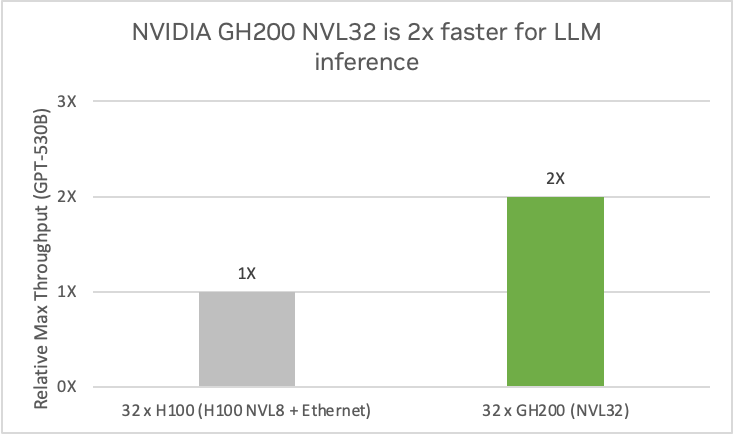
NVIDIA GH200 NVL32 muestra un rendimiento de inferencia de modelos GPT-3 530B 2x más rápido en comparación con H100 NVL8 con 80 GB de memoria GPU. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
El sistema NVIDIA GH200 NVL32 multiplica por 2 el rendimiento de cuatro sistemas H100 NVL8 con un modelo de inferencia GPT-530B. El gran espacio de memoria también mejora la eficiencia operativa, ya que permite almacenar varios modelos en el mismo nodo e intercambiarlos rápidamente para maximizar su utilización.
Sistemas de recomendación
Los sistemas de recomendación son el motor del Internet personalizado. Se utilizan en comercio electrónico y minorista, medios de comunicación y redes sociales, anuncios digitales, etc. para personalizar contenidos. Esto genera ingresos y valor empresarial. Los recomendadores utilizan incrustaciones que representan a los usuarios, los productos, las categorías y el contexto, y pueden tener un tamaño de hasta decenas de terabytes.
Un sistema de recomendación muy preciso proporcionará una experiencia de usuario más atractiva, pero también requiere una incrustación mayor. Las incrustaciones tienen características únicas para los modelos de IA, ya que requieren grandes cantidades de memoria con un gran ancho de banda y una conexión en red ultrarrápida.
NVIDIA GH200 NVL32 con Grace Hopper proporciona 7 veces más cantidad de memoria de acceso rápido en comparación con cuatro HGX H100 y proporciona 7 veces más ancho de banda en comparación con las conexiones PCIe Gen5 a la GPU en diseños convencionales basados en x86. Permite incrustaciones 7 veces más detalladas en comparación con las H100 con x86.
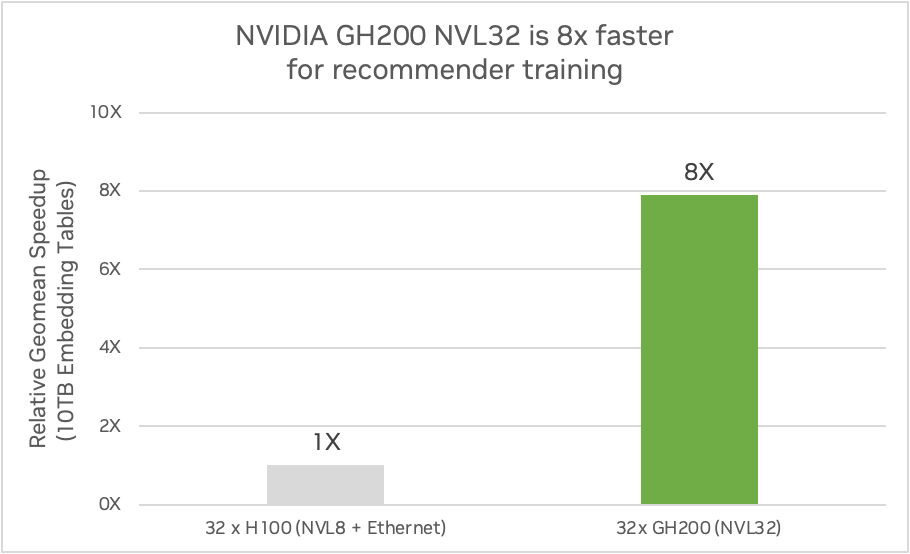
También puede proporcionar hasta 7,9 veces más rendimiento de entrenamiento para modelos con tablas de incrustación masivas. La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando un modelo DLRM. Las comparaciones se realizaron entre los sistemas GH200 y H100 utilizando tablas de incrustación de 10 TB y utilizando tablas de incrustación de 2 TB.
Comparación de un sistema NVIDIA GH200 NVL32 con cuatro servidores HGX H100 en la formación de recomendadores. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Redes neuronales gráficas
Las GNN (Graph Neural Networks) aplican el poder predictivo del aprendizaje profundo a ricas estructuras de datos que representan objetos y sus relaciones como puntos conectados por líneas en un gráfico. Muchas ramas de la ciencia y la industria ya almacenan datos valiosos en bases de datos de gráficos.
El aprendizaje profundo se utiliza para entrenar modelos predictivos que descubren nuevas perspectivas a partir de gráficos. Cada vez son más las organizaciones que aplican las GNN para mejorar el descubrimiento de fármacos, la detección de fraudes, la infografía, la ciberseguridad, la genómica, la ciencia de los materiales y los sistemas de recomendación. En la actualidad, los gráficos más complejos procesados por GNN tienen miles de millones de nodos, billones de aristas y funciones repartidas entre nodos y aristas.
NVIDIA GH200 NVL32 proporciona memoria masiva de CPU-GPU para almacenar estas complejas estructuras de datos y acelerar el cálculo. Además, los algoritmos de gráficos a menudo requieren accesos aleatorios a estos grandes conjuntos de datos que almacenan las propiedades de los vértices.
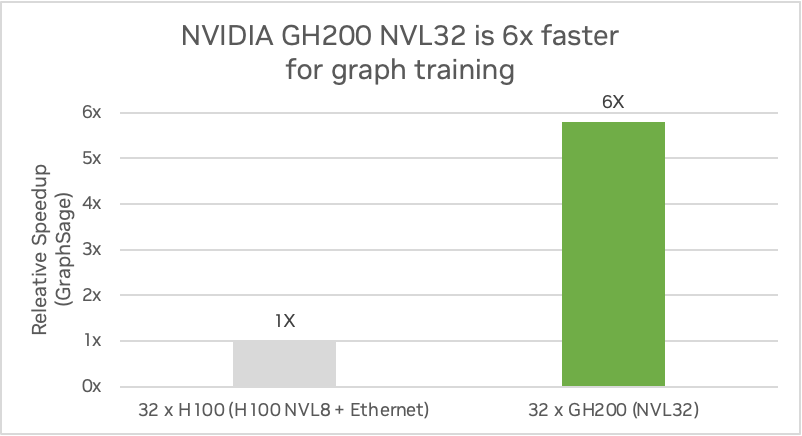
Estos accesos suelen verse limitados por el ancho de banda de las comunicaciones entre nodos. La conectividad GPU-GPU NVLink de NVIDIA GH200 NVL32 proporciona una enorme aceleración de estos accesos aleatorios. GH200 NVL32 puede aumentar el rendimiento de entrenamiento de GNN hasta 5,8 veces en comparación con NVIDIA H100.
La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando GraphSAGE. GraphSAGE es un marco inductivo general para generar de forma eficiente incrustaciones de nodos para datos no vistos previamente.
Comparación de un sistema NVIDIA GH200 NVL32 con cuatro servidores HGX H100 en el entrenamiento de gráficos. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Resumen
Amazon y NVIDIA han anunciado la llegada de NVIDIA DGX Cloud a AWS. AWS será el primer proveedor de servicios en la nube en ofrecer NVIDIA GH200 NVL32 en DGX Cloud y como instancia EC2. La solución NVIDIA GH200 NVL32 cuenta con un dominio NVLink de 32 GPU y 19,5 TB de memoria unificada. Esta configuración supera con creces a los modelos anteriores en el entrenamiento GPT-3 y la inferencia LLM.
La interconexión de memoria CPU-GPU de la NVIDIA GH200 NVL32 es extraordinariamente rápida, lo que mejora la disponibilidad de memoria para las aplicaciones. Esta tecnología forma parte de un modelo escalable para centros de datos de hiperescala, respaldado por un completo paquete de software y librerías de NVIDIA, que acelera miles de aplicaciones de GPU. NVIDIA GH200 NVL32 es ideal para tareas como el entrenamiento y la inferencia de LLM, los sistemas de recomendación y las GNN, entre otras, ya que ofrece mejoras significativas del rendimiento de las aplicaciones de IA y computación.
Administra, supervisa y optimiza tu infraestructura empresarial con la nube híbrida de Asus y Microsoft
La combinación de la tecnología de nube híbrida con soluciones basadas en software define una propuesta integral de ASUS.
Microsoft Azure Stack HCI fusiona la versatilidad de la nube híbrida con una plataforma de infraestructura hiperconvergente. De esta forma, unifica computación, almacenamiento y redes a través de definiciones basadas en software.
La colaboración entre ASUS y Microsoft ha dado lugar a una solución validada de Azure Stack HCI específicamente adaptada para sistemas de servidores ASUS, ofreciendo un rendimiento, escalabilidad y alta disponibilidad sin igual. La gestión de las implementaciones de HCI se vuelve más sencilla e integrada mediante la incorporación del Windows Admin Center.
Plataforma de centro de datos híbrida única
La singularidad de esta plataforma se aprecia en su soporte nativo para Azure, que permite ampliar el centro de datos, maximizando así las inversiones actuales y obteniendo nuevas capacidades híbridas integradas.
Infraestructura hiperconvergente sin precedentes
Las características hiperconvergentes marcan un hito en la escalabilidad del almacenamiento y la capacidad informática para los profesionales de TI, gracias a la tecnología de Windows Server 2022, lo que se traduce en un valor añadido más rápido.
Centro de administración de Windows
El Centro de Administración de Windows ofrece una interfaz única basada en navegador para la gestión remota de HCI, incorporando configuraciones definidas por software y el monitoreo de cargas de trabajo tanto locales como en Azure.
Capacidades de seguridad mejoradas
En términos de seguridad, se fortalece la protección y se minimiza el impacto de posibles amenazas de malware al aislar distintas cargas de trabajo en máquinas virtuales separadas, a través de un tejido de virtualización seguro.
NC Dual Xeon SP4/5-4B
Las configuraciones escalables en un sistema de 1U proporcionan aceleración optimizada para cargas de trabajo en centros de datos locales.
Perfecto para entornos de nube híbrida en informática financiera, aprendizaje automático, almacenamiento computacional y búsqueda y análisis de datos.
El fenómeno Barbenheimer (llamado así por la fusión de los títulos de las películas Barbie y Oppenheimer), que surgió por el estreno simultáneo de ambas y que fueron objeto de una gran expectación, es un buen ejemplo de cómo los avances tecnológicos están transformando la industria cinematográfica.
La industria cinematográfica es una de las más dinámicas e innovadoras del mundo, que ha experimentado una profunda transformación en las últimas décadas gracias al desarrollo de la tecnología, la inteligencia artificial y la infraestructura hardware. Estos avances han tenido un impacto en todas las etapas de la producción, distribución y exhibición de las películas, así como en el acceso y la democratización del cine, generando nuevos retos y oportunidades para los creadores y consumidores de contenidos audiovisuales.
Estas películas son una muestra de cómo la tecnología ha permitido crear nuevas formas de narrar historias en el cine, utilizando efectos especiales, realidad virtual, animación por ordenador y otros recursos visuales para recrear mundos fantásticos o históricos. Ambos filmes son un testimonio del poder de la IA para transformar la industria cinematográfica.
Barbie: creando Barbieland
Fotograma de Barbie
Barbie es un ejemplo de cómo la IA puede utilizarse para crear películas de animación que son visualmente impresionantes y atractivas para el público.
La capacidad gráfica de estaciones de trabajo potentes e innovadoras permitió crear el deslumbrante y fantástico mundo animado de Barbieland. Los diseñadores pudieron dar rienda suelta a su imaginación para construir sets elaborados y personajes vibrantes que hubieran sido imposibles sin una infraestructura hardware.
Oppenheimer: un enfoque visual histórico impresionante
Cartel de Oppenheimer
En Oppenheimer, la revolución tecnológica se refleja en el enfoque visual de la película. Utiliza efectos visuales de última generación para recrear momentos históricos como los eventos del proyecto Manhattan y la detonación de la primera bomba atómica con un alto grado de precisión.
Oppenheimer es un ejemplo de cómo la IA puede utilizarse para crear películas de acción real que son históricamente precisas y emocionalmente resonantes.
Barbenheimer: la convergencia de la creatividad y el realismo
Estas películas muestran cómo los avances tecnológicos, la inteligencia artificial y la infraestructura hardware han potenciado el poder de contar historias y la capacidad para abordar temas relevantes y complejos de manera innovadora.
La tecnología ha tenido un efecto transformador en todas las etapas de la producción, distribución y exhibición de las películas. El uso de cámaras digitales, drones, pantallas de croma, realidad virtual y efectos especiales ha permitido crear imágenes más realistas, espectaculares y creativas, que captan la atención y la emoción del espectador. La tecnología también ha facilitado el proceso de edición, montaje y sonorización de las películas; permitiendo corregir errores, mejorar la calidad y añadir elementos que no se pudieron captar durante el rodaje. La tecnología ha hecho posible también la creación de nuevas plataformas y formatos de visualización, como el cine 3D, 4D o IMAX, que ofrecen una experiencia más inmersiva e interactiva al espectador.
Más allá de los efectos visuales, la IA está empezando a desempeñar roles más activos en la industria cinematográfica. Algoritmos de aprendizaje automático pueden analizar guiones y proveer insights sobre cómo mejorar la trama, los diálogos y la caracterización de personajes.
Si bien aún falta para ver IA creando guiones enteros o dirigiendo películas, su influencia como herramienta creativa es indiscutible. Barbenheimer es apenas un vistazo al potencial de contar historias impactantes de nuevas maneras gracias a los avances tecnológicos. La simbiosis entre arte cinematográfico y tecnología ha llegado para quedarse. Esta nueva era promete ser muy emocionante tanto para cineastas como para audiencias ávidas de nuevas experiencias.
La arquitectura de las tarjetas gráficas AMD Radeon™ PRO para workstations
La avanzada arquitectura de las GPU AMD Radeon™ PRO, AMD RDNA, se presentó por primera vez en 2019 y, desde entonces, ha evolucionado hasta convertirse en AMD RDNA 2. Esta arquitectura es la base de los gráficos que alimentan las consolas de juegos y los PC líderes y visualmente enriquecidos. Ahora, AMD RDNA 2 está disponible en la gama profesional de tarjetas gráficas Radeon PRO™ W6000.
La arquitectura gráfica AMD RDNA 2 ofrece más libertad a la hora de trabajar con conjuntos de datos más grandes de manera más rápida.
Mayor rendimiento profesional
Diseñada desde cero con un rendimiento y una eficiencia energética superiores, la arquitectura AMD RDNA 2 ofrece un rendimiento hasta un 194% más rápido respecto a la arquitectura GCN de la generación anterior, con el soporte añadido de Variable Rate Shading (VRS), para un rendimiento de renderizado de fotogramas inteligente, y Vulkan 1.2 y DirectX 12 Ultimate, para un rendimiento gráfico de última generación en software profesional compatible.
Generaciones de arquitectura gráfica
Fuente: AMD
Importancia para el software profesional
La arquitectura AMD RDNA 2 introduce avances significativos en forma de una nueva AMD Infinity Cache. Una unidad de cómputo mejorada, soporte de Raytracing en hardware, combinado con un nuevo pipeline visual para una mayor eficiencia. En el siguiente apartado exploraremos el significado de cada uno de estos términos y, cuando se combinan, cómo estos avances ayudan a conseguir un rendimiento de alta resolución y unas imágenes más vívidas con el software profesional que elijas.
Nueva tecnología AMD Infinity Cache
AMD Infinity Cache
La arquitectura AMD RDNA 2 es más eficiente gracias a la introducción de AMD Infinity Cache. Un nivel de caché adicional totalmente nuevo que permite un rendimiento de gran ancho de banda con bajo consumo y baja latencia, ayudando a eliminar los cuellos de botella de los datos. Esta caché global está contemplada por todo el núcleo gráfico, capturando la «reutilización temporal» (reutilización optimizada e iterativa de los mismos datos) y permitiendo acceder a los datos de forma prácticamente instantánea. Aprovechando los mejores enfoques de procesamiento de datos de alta frecuencia de la arquitectura «Zen», AMD Infinity Cache permite un rendimiento escalable.
Unidades de cálculo mejoradas
Cada unidad de cálculo (CU) del chip alberga varios procesadores de flujo y núcleos. Cuanto mayor es el número de núcleos de una tarjeta gráfica, más potente suele ser. Cada núcleo está duplicado para trabajar en tareas paralelas enviadas desde el software del usuario, como la visualización de imágenes en la pantalla o el cálculo científico. Forman el cerebro central del procesador gráfico.
Trazado de rayos (ray tracing) con aceleración por hardware
Una novedad de la Unidad de Cálculo AMD RDNA 2 es la implementación de una arquitectura de aceleración de trazado de rayos de alto rendimiento conocida como Aceleradores de Rayos, que ofrece un mayor realismo visual en su software compatible. Es un hardware especializado que maneja eficientemente la compleja intersección de cálculos de rayos diseñados para acelerar este proceso, en comparación con el software únicamente.
Las últimas GPU con certificación profesional: AMD Radeon™ PRO
AMD Radeon™ PRO cuenta con una arquitectura creada para profesionales
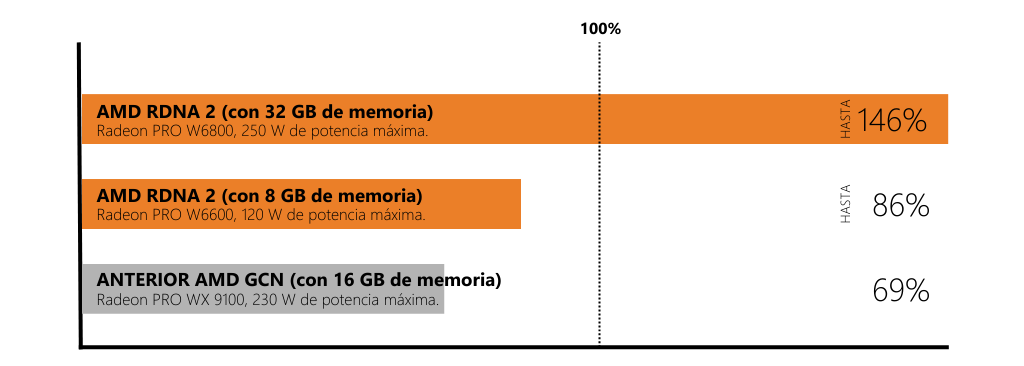
Una arquitectura gráfica es compleja y, además, necesita serlo para las tareas diarias que se lanzan. Estas tecnologías avanzadas de AMD ayudan a eliminar los cuellos de botella habituales de la GPU y el sistema, lo que permite mejorar el rendimiento. Aunque esto suena muy bien, en última instancia lo que importa es el impacto en el software, y en el siguiente gráfico podemos ver solo uno de los muchos ejemplos de aumentos de rendimiento mejorados, pero asequibles, con las GPU AMD Radeon™ PRO, mientras se utiliza menos potencia pico comparativa.
La criomicroscopía electrónica es una técnica muy utilizada en el campo de la biología para el estudio de estructuras moleculares a temperaturas criogénicas; lo que permite observar las muestras a resolución atómica.
Jackes Dubochet, Joachim Frank y Richard Henderson ganaron el Premio Nobel de Química por su trabajo en el desarrollo de la criomicroscopía electrónica en el año 2017.
La metodología que sigue esta técnica es la siguiente:
La muestra se congela y se prepara con hielo vítreo.
Se realiza la toma de imágenes.
Se digitalizan las imágenes.
Las imágenes ya digitalizadas en 2D se procesan para obtener una reconstrucción 3D de las estructuras macromoleculares.
Los avances tecnológicos (como los microscopios que trabajan, entre otras cosas, con GPUs que aceleran el procesamiento de imágenes) y la evolución en la potencia de cómputo han facilitado la elaboración de los modelos tridimensionales.
El servicio de criomicroscopía electrónica
Con sede en el Centro Nacional de Biotecnología (CNB), la instalación de criomicroscopía electrónica (Cryo-EM) del CSIC es un servicio básico de última generación que ofrece tanto la preparación de muestras como la recopilación de imágenes Cryo-EM de material biológico.
La instalación alberga dos criomicroscopios electrónicos:
Un JEOL CryoARM de 300 kV equipado con un cargador automático, un detector de electrones directos Gatan K3 y un filtro de energía Omega.
Un FEI TALOS Arctica de 200 kV, equipado con un cargador automático y un detector de electrones directos Falcon III.
Ambos son adecuados para la recopilación de grandes cantidades de datos de alta resolución.
Esta instalación, única en España, cuenta también con dos dispositivos adecuados para la vitrificación de muestras pequeñas, como proteínas y complejos macromoleculares y un tercer dispositivo adecuado para la congelación rápida de muestras celulares.
“El primer paso de esta técnica (la criomicroscopía electrónica) consiste en congelar las proteínas a muy baja temperatura (-180ºC), de tal manera que movilizamos las proteínas en una capa fina de hielo, quedando inmersas y dispuestas en distintas orientaciones.
Posteriormente, introducimos las proteínas en el microscopio electrónico de transmisión y capturamos un gran número de imágenes que, gracias a potentes ordenadores, muestran la estructura de estas proteínas en alta resolución. Incluso, podemos visualizar los aminoácidos que componen estas proteínas.
Con la utilización de esta técnica ayudamos al desarrollo de nuevos fármacos”.
Rocío Arranz, jefa del Servicio de Criomicroscopía Electrónica del Centro Nacional de Biotecnología del CSIC (CNB-CSIC)
BREM
El Basque Resource for Electron Microscopy (BREM) proporciona acceso a instrumentación de alta gama y experiencia en criomicroscopía electrónica de alta resolución (Cryo-EM) a investigadores nacionales e internacionales, académicos e industriales.
Está ubicado en el Instituto de Biofisika (CSIC) en el parque científico de la Universidad del País Vasco en Leioa; y está apoyado por la fundación Biofísica Bizkaia. Es parte de una iniciativa ambiciosa del Departamento de Educación y el Fondo de Innovación del Gobierno Vasco para incorporar tecnologías disruptivas que tengan un impacto importante en el desarrollo tecnológico, de investigación y de innovación.
El objetivo de BREM es comprender la base estructural de los procesos biológicos y la patogénesis de las enfermedades humanas a través de la criomicroscopía electrónica.
Además, también apoya los esfuerzos de investigación de fármacos basados en biología estructural y el desarrollo de terapias avanzadas para enfermedades.
BREM ha instalado un microscopio electrónico de transmisión Thermo Fisher Titan Krios G4; es el primero en España y el segundo en el sur de Europa. Cuenta con personal altamente cualificado y ayuda a los usuarios con la determinación de la estructura tridimensional utilizando todas las técnicas principales Cryo-EM disponibles para la biología estructural.
«La llegada de este microscopio electrónico al Instituto Biofisika nos permite participar en proyectos internacionales de interés biomédico; por lo tanto, podemos competir y posicionar al País Vasco en una primera línea en biología estructural».
David Gil Carton, director técnico de BREM
Características del criomicroscopio electrónico de BREM
El criomicroscopio electrónico instalado en el Instituto Biofisika para la observación de especímenes biológicos a baja temperatura mediante criomicroscopía electrónica tiene las siguientes características:
Se trata de un criomicroscopio electrónico de transmisión de 300 kV de alta resolución de última generación.
Utiliza lentes de alta estabilidad y un cañón de emisión de campo como fuente de iluminación.
Cuenta con una placa de fase para la mejora del contraste.
Incluye un filtro de energía y un detector directo de electrones como sistema de recogida de información.
Está optimizado para el análisis automatizado de partículas individuales, microdifracción de electrones y la tomografía electrónica de doble eje.
Consigue imágenes de muestras biológicas a baja temperatura con una resolución ultra alta para la adquisición de datos con un alto rendimiento y reproducibilidad; y de manera simple e intuitiva.
La aportación de Azken a la criomicroscopía electrónica
BREM planteó un reto a Azken Muga:
“El éxito de este microscopio es su gran capacidad de automatización, la mejora en estabilidad y el mayor rendimiento de los nuevos detectores.
Todo esto hace posible realizar sesiones ininterrumpidas de 48 horas de un solo experimento. Estos datos pueden ser 10, 20 o 40 Tb, dependiendo del experimento; luego, tanto el control de calidad para toma de decisiones en tiempo real («processing on-the-fly») como la transferencia de datos a los usuarios lo más rápido -y sin fallos- es vital para el éxito de BREM.
Los datos son movies (vídeos) de 1 Gb cada uno en formato MRC o TIFF y en un solo experimento hay que transferir al usuario desde 20.000 hasta 45.000 de estas movies. El microscopio puede generar 10.000 movies en 24 horas”.
David Gil Carton, director técnico de BREM
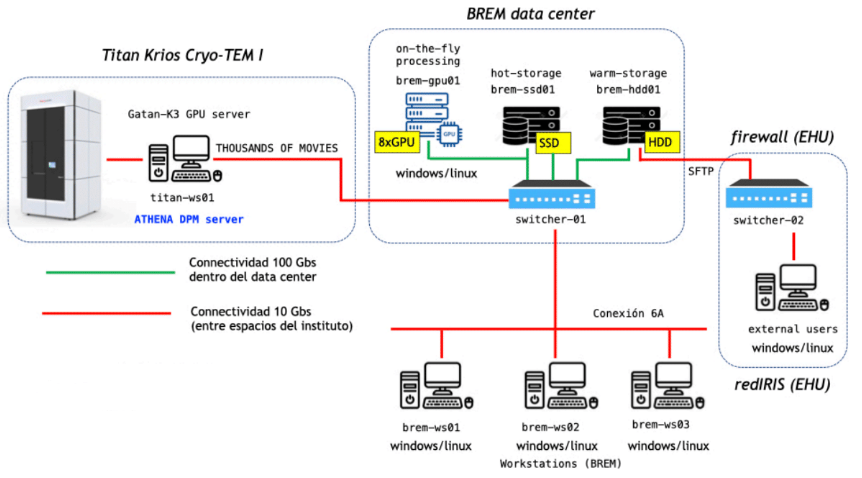
BREM requería por parte de Azken un data center, compuesto por un servidor 8xGPU, dos servidores de almacenamiento y tres workstations, conectado al servidor del microscopio. Siguiendo este esquema:
Fuente: BREM
Los sistemas elegidos para llevar a cabo este proyecto fueron: un servidor basado en GPU para el procesamiento de imágenes (8G4 Dual Xeon Scalable HPC 8xGPU); un servidor de almacenamiento SSD (RStorage 540S Dual Xeon Scalable Processors 36xSSD); un servidor de almacenamiento HDD (RStorage 540S Dual Xeon Scalable Processors 36xHDD); y tres workstations multi GPU de escritorio (T-Series Xeon SP).