En el ámbito de la mejora de la seguridad y la eficiencia en el transporte, la compañía ferroviaria nacional española, Renfe, buscaba una solución de seguridad avanzada.
Azken Muga, conocida por su destreza en la construcción de sistemas, aceptó el reto de desarrollar la «Estación Inteligente de Seguridad Renfe». El objetivo del proyecto era cumplir los estrictos requisitos de videovigilancia, garantizando fiabilidad, compatibilidad, flexibilidad y un rendimiento óptimo.
Por qué Kingston ha elegido Azken
Kingston Technology reconoció la importancia de una sólida colaboración para el éxito de una empresa tan innovadora. El historial de colaboraciones exitosas de Azken Muga y su compromiso de ofrecer soluciones de alta calidad los convirtieron en una elección obvia. Kingston apreció la confianza que Azken Muga depositó en sus productos, especialmente en los módulos DDR5 ValueRAM elegidos para los ordenadores CCTV AI.
La reputación de Azken Muga como constructor de sistemas fiable les convirtió en el socio ideal para este proyecto crítico. Su experiencia en la creación de soluciones que se integran a la perfección con los sistemas existentes y ofrecen un rendimiento de primera categoría fue fundamental. La trayectoria de la empresa y su compromiso con la excelencia encajaban perfectamente con los ambiciosos objetivos del proyecto.
Colaboración constante
Azken descubrió en Kingston un socio fiable e innovador.
El éxito del proyecto de la Estación de Seguridad Inteligente de Renfe ha reforzado la colaboración en curso. El aprecio de Kingston por la relación radica en el compromiso compartido con los objetivos futuros. A medida que Azken Muga sigue recurriendo a Kingston en busca de soluciones y un apoyo excepcional, la asociación se mantiene a la vanguardia de la innovación en el sector de la seguridad. Juntos, navegan por el siempre cambiante panorama de la tecnología de seguridad, garantizando la seguridad y la protección de clientes y usuarios por igual.
Las librerías de procesamiento de datos NVIDIA CUDA-X se integrarán en las soluciones de inteligencia artificial de Azken para acelerar las tareas de preparación y procesamiento de datos que constituyen la base del desarrollo de la inteligencia artificial generativa.
Basadas en la plataforma de cálculo NVIDIA CUDA, las librerías CUDA-X aceleran el procesamiento de una amplia variedad de tipos de datos, lo que incluye tablas, texto, imágenes y vídeo. Entre ellas se incluye la librería NVIDIA RAPIDS cuDF, que acelera hasta 110 veces el trabajo de los casi 10 millones de científicos de datos que utilizan el software pandas utilizando una GPU NVIDIA RTX 6000 Ada Generation en lugar de un sistema basado únicamente en CPU, sin necesidad de modificar el código.
«Pandas es la herramienta esencial de millones de científicos de datos que procesan y preparan datos para la IA generativa. Acelerar Pandas sin cambiar el código será un gran paso adelante. Los científicos de datos podrán procesarlos en minutos en lugar de en horas, y manejar órdenes de grandes magnitudes de datos para entrenar modelos de IA generativa».
Jensen Huang, fundador y CEO de NVIDIA.
Fuente: NVIDIA
Pandas proporciona una potente estructura de datos, denominada DataFrames, que permite a los desarrolladores manipular, limpiar y analizar fácilmente datos tabulares. La librería NVIDIA RAPIDS cuDF acelera pandas para que pueda ejecutarse en las GPU sin necesidad de modificar el código, en lugar de depender de las CPU, que pueden ralentizar las cargas de trabajo a medida que aumenta el tamaño de los datos. RAPIDS cuDF es compatible con librerías de terceros y unifica los flujos de trabajo de GPU y CPU para que los científicos de datos puedan desarrollar, probar y ejecutar modelos en producción sin problemas.
Se espera que NVIDIA RAPIDS cuDF para acelerar pandas sin cambiar el código esté disponible en las soluciones de estaciones de trabajo de IA de Azken con GPU NVIDIA RTX y GeForce RTX próximamente.
AWS será el primer proveedor de cloud computing en ofrecer los superchips NVIDIA GH200 Grace Hopper. Interconectados con la tecnología NVIDIA NVLink a través de NVIDIA DGX Cloud se ejecutarán en Amazon Elastic Compute Cloud (Amazon EC2).
Se trata de una tecnología revolucionaria para la computación en la nube.
NVIDIA GH200 NVL32 es una solución de rack escalable dentro de NVIDIA DGX Cloud o en las infraestructuras de Amazon. Cuenta con un dominio NVIDIA NVLink de 32 GPU y una enorme memoria unificada de 19,5 TB. Superando las limitaciones de memoria de un único sistema, es 1,7 veces más rápida para el entrenamiento GPT-3 y 2 veces más rápida para la inferencia de modelos de lenguaje de gran tamaño (LLM) en comparación con NVIDIA HGX H100.
Las infraestructuras de AWS equipadas con NVIDIA GH200 Grace Hopper Superchip contarán con 4,5 TB de memoria HBM3e. Esto supone un aumento de 7,2 veces en comparación con las EC2 P5 equipadas con NVIDIA H100. Esto permite a los desarrolladores ejecutar modelos de mayor tamaño y mejorar el rendimiento del entrenamiento.
Además, la interconexión de memoria de la CPU a la GPU es de 900 GB/s, 7 veces más rápida que PCIe Gen 5. Las GPU acceden a la memoria de la CPU de forma coherente con la caché, lo que amplía la memoria total disponible para las aplicaciones. Este es el primer uso del diseño escalable GH200 NVL32 de NVIDIA. Un diseño de referencia modular para supercomputación, centros de datos e infraestructuras en la nube. Proporciona una arquitectura común para las configuraciones de procesadores GH200 y sucesores.
En este artículo se explica la infraestructura que lo hace posible y se incluyen algunas aplicaciones representativas.
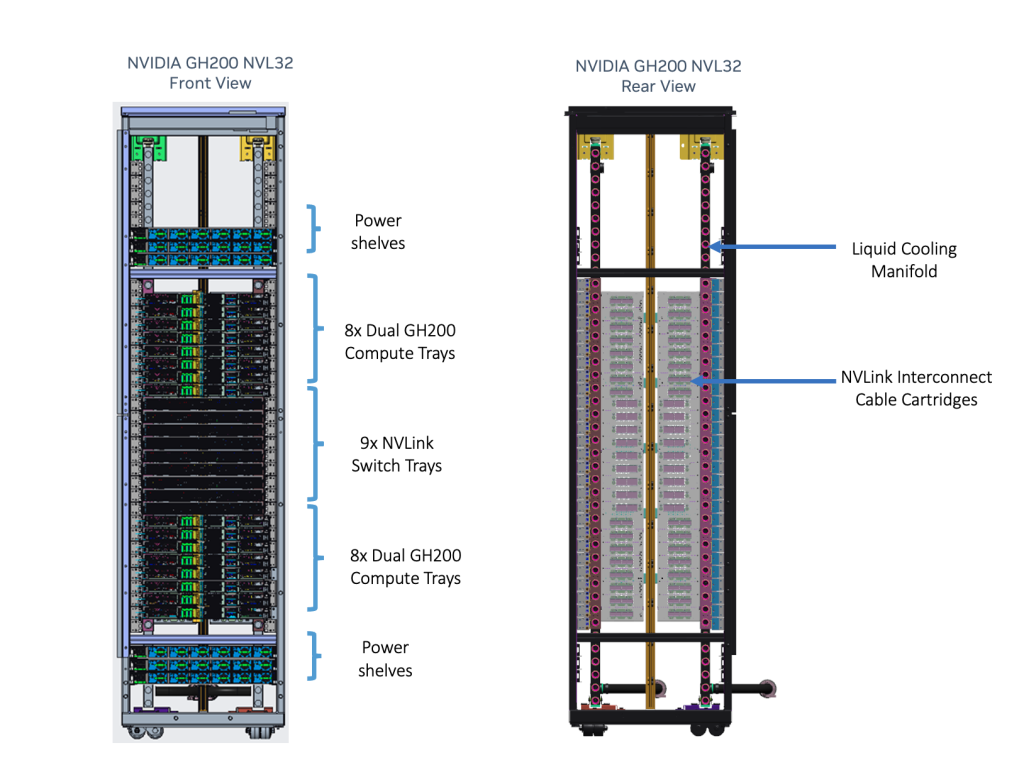
NVIDIA GH200 NVL32
NVIDIA GH200 NVL32 es un modelo de rack para los superchips NVIDIA GH200 Grace Hopper conectados a través de NVLink destinado a centros de datos de hiperescala. Admite 16 nodos de servidor Grace Hopper duales compatibles con el diseño de chasis NVIDIA MGX. Admite refrigeración líquida para maximizar la densidad y la eficiencia del cálculo.
NVIDIA GH200 NVL32 es una solución a escala de rack que ofrece un dominio NVLink de 32 GPU y 19,5 TB de memoria unificada. Fuente: NVIDIA
NVIDIA GH200 Grace Hopper Superchip con un NVLink-C2C coherente crea un espacio de direcciones de memoria direccionable NVLink para simplificar la programación de modelos. Combina memoria de sistema de gran ancho de banda y bajo consumo, LPDDR5X y HBM3e, para aprovechar al máximo la aceleración de la GPU NVIDIA y los núcleos Arm de alto rendimiento en un sistema bien equilibrado.
Los nodos del servidor GH200 están conectados con un cartucho de cable de cobre pasivo NVLink para permitir que cada GPU Hopper acceda a la memoria de cualquier otro Superchip Grace Hopper de la red. Lo que proporciona 32 x 624 GB, o 19,5 TB de memoria direccionable NVLink.
Esta actualización del sistema de conmutación NVLink utiliza la interconexión de cobre NVLink para conectar 32 GPU GH200 mediante nueve conmutadores NVLink que incorporan chips NVSwitch de tercera generación. El sistema de conmutación NVLink implementa una red fat-tree totalmente conectada para todas las GPU del cluster. Para necesidades de mayor escala, el escalado con InfiniBand o Ethernet a 400 Gb/s proporciona un rendimiento increíble y una solución de supercomputación de IA de bajo consumo energético.
NVIDIA GH200 NVL32 es compatible con el SDK HPC de NVIDIA y el conjunto completo de librerías CUDA, NVIDIA CUDA-X y NVIDIA Magnum IO. Lo que permite acelerar más de 3.000 aplicaciones de GPU.
Casos de uso y resultados de rendimiento
NVIDIA GH200 NVL32 es ideal para el entrenamiento y la inferencia de la IA, los sistemas de recomendación, las redes neuronales de grafos (GNN), las bases de datos vectoriales y los modelos de generación aumentada por recuperación (RAG), como se detalla a continuación.
Entrenamiento e inferencia de IA
La IA generativa ha irrumpido con fuerza en todo el mundo, como demuestran las revolucionarias capacidades de servicios como ChatGPT. LLMs como GPT-3 y GPT-4 están permitiendo la integración de capacidades de IA en todos los productos de todas las industrias, y su tasa de adopción es asombrosa.
ChatGPT se convirtió en la aplicación que más rápido alcanzó los 100 millones de usuarios, logrando ese hito en sólo 2 meses. La demanda de aplicaciones de IA generativa es inmensa y crece exponencialmente.
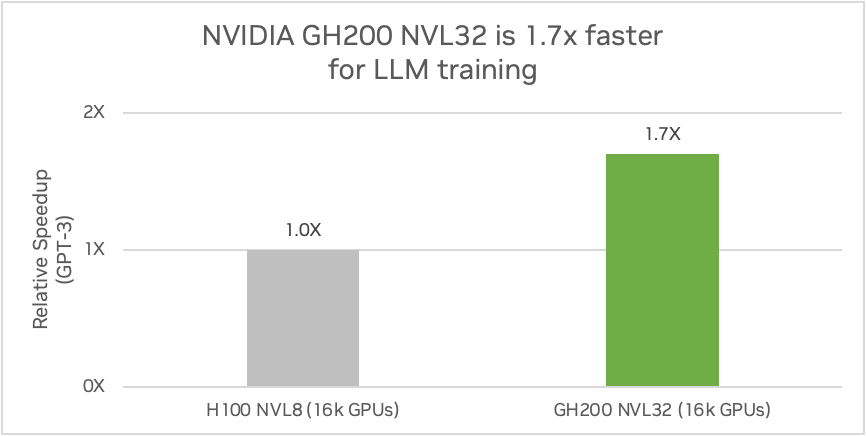
Un centro de datos Ethernet con 16.000 GPUs que utilice NVIDIA GH200 NVL32 ofrecerá 1,7 veces más rendimiento que uno compuesto por H100 NVL8, que es un servidor NVIDIA HGX H100 con ocho GPUs H100 conectadas mediante NVLink. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Los LLM requieren un entrenamiento a gran escala y multi-GPU. Los requisitos de memoria para GPT-175B serían de 700 GB, ya que cada parámetro necesita cuatro bytes (FP32). Se utiliza una combinación de paralelismo de modelos y comunicaciones rápidas para evitar quedarse sin memoria con GPU de memoria más pequeña.
NVIDIA GH200 NVL32 está diseñada para la inferencia y el entrenamiento de la próxima generación de LLM. Al superar los cuellos de botella de memoria, comunicaciones y cálculo con 32 superchips Grace Hopper GH200 conectados por NVLink, el sistema puede entrenar un modelo de un billón de parámetros 1,7 veces más rápido que NVIDIA HGX H100.
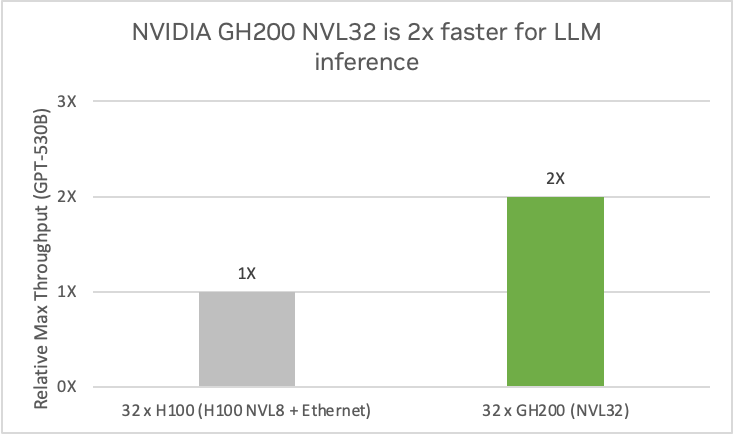
NVIDIA GH200 NVL32 muestra un rendimiento de inferencia de modelos GPT-3 530B 2x más rápido en comparación con H100 NVL8 con 80 GB de memoria GPU. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
El sistema NVIDIA GH200 NVL32 multiplica por 2 el rendimiento de cuatro sistemas H100 NVL8 con un modelo de inferencia GPT-530B. El gran espacio de memoria también mejora la eficiencia operativa, ya que permite almacenar varios modelos en el mismo nodo e intercambiarlos rápidamente para maximizar su utilización.
Sistemas de recomendación
Los sistemas de recomendación son el motor del Internet personalizado. Se utilizan en comercio electrónico y minorista, medios de comunicación y redes sociales, anuncios digitales, etc. para personalizar contenidos. Esto genera ingresos y valor empresarial. Los recomendadores utilizan incrustaciones que representan a los usuarios, los productos, las categorías y el contexto, y pueden tener un tamaño de hasta decenas de terabytes.
Un sistema de recomendación muy preciso proporcionará una experiencia de usuario más atractiva, pero también requiere una incrustación mayor. Las incrustaciones tienen características únicas para los modelos de IA, ya que requieren grandes cantidades de memoria con un gran ancho de banda y una conexión en red ultrarrápida.
NVIDIA GH200 NVL32 con Grace Hopper proporciona 7 veces más cantidad de memoria de acceso rápido en comparación con cuatro HGX H100 y proporciona 7 veces más ancho de banda en comparación con las conexiones PCIe Gen5 a la GPU en diseños convencionales basados en x86. Permite incrustaciones 7 veces más detalladas en comparación con las H100 con x86.
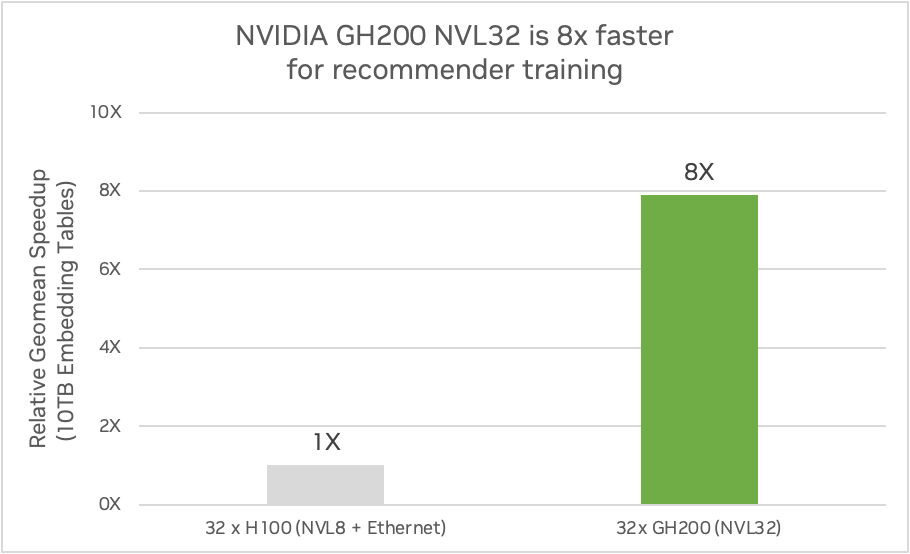
También puede proporcionar hasta 7,9 veces más rendimiento de entrenamiento para modelos con tablas de incrustación masivas. La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando un modelo DLRM. Las comparaciones se realizaron entre los sistemas GH200 y H100 utilizando tablas de incrustación de 10 TB y utilizando tablas de incrustación de 2 TB.
Comparación de un sistema NVIDIA GH200 NVL32 con cuatro servidores HGX H100 en la formación de recomendadores. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Redes neuronales gráficas
Las GNN (Graph Neural Networks) aplican el poder predictivo del aprendizaje profundo a ricas estructuras de datos que representan objetos y sus relaciones como puntos conectados por líneas en un gráfico. Muchas ramas de la ciencia y la industria ya almacenan datos valiosos en bases de datos de gráficos.
El aprendizaje profundo se utiliza para entrenar modelos predictivos que descubren nuevas perspectivas a partir de gráficos. Cada vez son más las organizaciones que aplican las GNN para mejorar el descubrimiento de fármacos, la detección de fraudes, la infografía, la ciberseguridad, la genómica, la ciencia de los materiales y los sistemas de recomendación. En la actualidad, los gráficos más complejos procesados por GNN tienen miles de millones de nodos, billones de aristas y funciones repartidas entre nodos y aristas.
NVIDIA GH200 NVL32 proporciona memoria masiva de CPU-GPU para almacenar estas complejas estructuras de datos y acelerar el cálculo. Además, los algoritmos de gráficos a menudo requieren accesos aleatorios a estos grandes conjuntos de datos que almacenan las propiedades de los vértices.
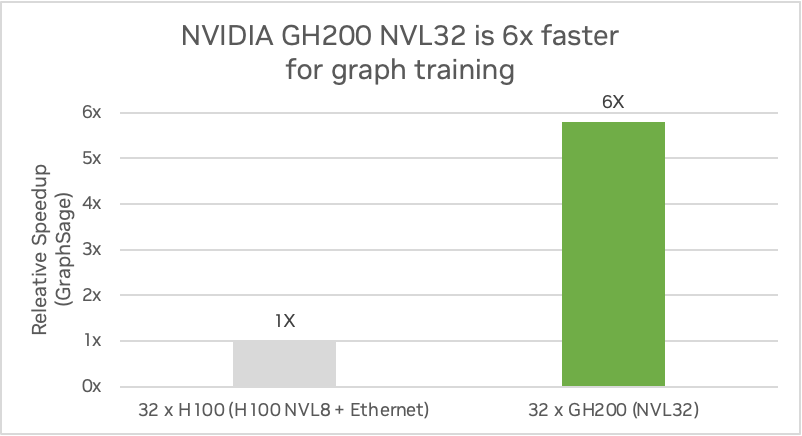
Estos accesos suelen verse limitados por el ancho de banda de las comunicaciones entre nodos. La conectividad GPU-GPU NVLink de NVIDIA GH200 NVL32 proporciona una enorme aceleración de estos accesos aleatorios. GH200 NVL32 puede aumentar el rendimiento de entrenamiento de GNN hasta 5,8 veces en comparación con NVIDIA H100.
La siguiente figura muestra una comparación de un sistema GH200 NVL32 con 144 GB de memoria HBM3e e interconexión NVLink de 32 vías frente a cuatro servidores HGX H100 con 80 GB de memoria HBM3 conectados con interconexión NVLink de 8 vías utilizando GraphSAGE. GraphSAGE es un marco inductivo general para generar de forma eficiente incrustaciones de nodos para datos no vistos previamente.
Comparación de un sistema NVIDIA GH200 NVL32 con cuatro servidores HGX H100 en el entrenamiento de gráficos. (Estimaciones preliminares de rendimiento sujetas a cambios). Fuente: NVIDIA
Resumen
Amazon y NVIDIA han anunciado la llegada de NVIDIA DGX Cloud a AWS. AWS será el primer proveedor de servicios en la nube en ofrecer NVIDIA GH200 NVL32 en DGX Cloud y como instancia EC2. La solución NVIDIA GH200 NVL32 cuenta con un dominio NVLink de 32 GPU y 19,5 TB de memoria unificada. Esta configuración supera con creces a los modelos anteriores en el entrenamiento GPT-3 y la inferencia LLM.
La interconexión de memoria CPU-GPU de la NVIDIA GH200 NVL32 es extraordinariamente rápida, lo que mejora la disponibilidad de memoria para las aplicaciones. Esta tecnología forma parte de un modelo escalable para centros de datos de hiperescala, respaldado por un completo paquete de software y librerías de NVIDIA, que acelera miles de aplicaciones de GPU. NVIDIA GH200 NVL32 es ideal para tareas como el entrenamiento y la inferencia de LLM, los sistemas de recomendación y las GNN, entre otras, ya que ofrece mejoras significativas del rendimiento de las aplicaciones de IA y computación.
La seguridad de la información es un aspecto clave para el éxito de cualquier organización en el mundo actual. Por eso, en Azken Muga nos hemos comprometido a proteger la información de nuestros clientes, empleados y socios, y a cumplir con las normas legales y éticas que nos aplican.
Para demostrar nuestro compromiso, hemos implementado y mantenido un Sistema de Gestión de Seguridad de la Información (SGSI) basado en la norma internacional ISO 27001. Esta norma establece los requisitos para identificar, analizar y gestionar los riesgos de seguridad de la información. Así como para establecer los controles necesarios para garantizar la confidencialidad, integridad y disponibilidad de la información.
Los beneficios de la norma ISO 27001
El certificado ISO 27001 tiene muchos beneficios. Algunos de ellos son:
Aumenta nuestra credibilidad y reputación como organización responsable y confiable, que se preocupa por la seguridad de la información.
Nos ayuda a cumplir con las obligaciones legales y regulatorias que nos afectan. Como el Reglamento General de Protección de Datos (RGPD) o la Ley Orgánica de Protección de Datos y Garantía de los Derechos Digitales (LOPDGDD).
Nos permite ofrecer un mejor servicio a nuestros clientes, al asegurar la protección de sus datos personales y de su información sensible; y al evitar incidentes o brechas de seguridad que puedan afectar a su satisfacción o fidelidad.
Nos facilita el acceso a nuevos mercados y oportunidades de negocio, al ser un requisito o un factor diferencial para algunos clientes o sectores que demandan altos niveles de seguridad de la información.
Nos aporta una ventaja competitiva frente a otras empresas que no cuentan con el certificado ISO 27001. O que tienen sistemas de seguridad de la información menos robustos o eficaces.
Nos ayuda a mejorar nuestro rendimiento y nuestra eficiencia, al optimizar nuestros procesos, recursos y tecnologías relacionados con la seguridad de la información; y al reducir los costes asociados a los incidentes o las pérdidas de información.
Nos implica a todos los miembros de la organización en la cultura de la seguridad de la información, al fomentar la concienciación, la formación y la participación de todos los niveles y áreas de la empresa.
Nuestros compromisos
Así mismo, mediante la elaboración e implantación del presente SGSI, Azken adquiere los siguientes compromisos:
Desarrollar productos y servicios conformes con los requisitos legislativos, identificando para ello las legislaciones de aplicación a las líneas de negocio desarrolladas por la organización e incluidas en el alcance del Sistema de Gestión de la Seguridad de la Información.
Establecimiento y cumplimiento de los requisitos contractuales con las partes interesadas.
Definir los requisitos de formación en seguridad y proporcionar la formación necesaria en dicha materia a las partes interesadas, mediante el establecimiento de planes de formación.
Prevención y detección de virus y otro software malicioso, mediante el desarrollo de políticas específicas y el establecimiento de acuerdos contractuales con organizaciones especializadas.
Gestión de la continuidad del negocio, desarrollando planes de continuidad conformes a metodologías de reconocido prestigio internacional.
Establecimiento de las consecuencias de las violaciones de la política de seguridad. Estas serán reflejadas en los contratos firmados con las partes interesadas, proveedores y subcontratistas.
Actuar en todo momento dentro de la más estricta ética profesional.
En definitiva, el certificado ISO 27001 es un logro que nos llena de orgullo y que nos motiva a seguir trabajando por la seguridad de la información.
Esperamos que este artículo os haya servido para conocer mejor el certificado ISO 27001 y sus beneficios. Y que os animéis a seguirnos en nuestras redes sociales, donde compartiremos más noticias y novedades sobre nuestra empresa.
Administra, supervisa y optimiza tu infraestructura empresarial con la nube híbrida de Asus y Microsoft
La combinación de la tecnología de nube híbrida con soluciones basadas en software define una propuesta integral de ASUS.
Microsoft Azure Stack HCI fusiona la versatilidad de la nube híbrida con una plataforma de infraestructura hiperconvergente. De esta forma, unifica computación, almacenamiento y redes a través de definiciones basadas en software.
La colaboración entre ASUS y Microsoft ha dado lugar a una solución validada de Azure Stack HCI específicamente adaptada para sistemas de servidores ASUS, ofreciendo un rendimiento, escalabilidad y alta disponibilidad sin igual. La gestión de las implementaciones de HCI se vuelve más sencilla e integrada mediante la incorporación del Windows Admin Center.
Plataforma de centro de datos híbrida única
La singularidad de esta plataforma se aprecia en su soporte nativo para Azure, que permite ampliar el centro de datos, maximizando así las inversiones actuales y obteniendo nuevas capacidades híbridas integradas.
Infraestructura hiperconvergente sin precedentes
Las características hiperconvergentes marcan un hito en la escalabilidad del almacenamiento y la capacidad informática para los profesionales de TI, gracias a la tecnología de Windows Server 2022, lo que se traduce en un valor añadido más rápido.
Centro de administración de Windows
El Centro de Administración de Windows ofrece una interfaz única basada en navegador para la gestión remota de HCI, incorporando configuraciones definidas por software y el monitoreo de cargas de trabajo tanto locales como en Azure.
Capacidades de seguridad mejoradas
En términos de seguridad, se fortalece la protección y se minimiza el impacto de posibles amenazas de malware al aislar distintas cargas de trabajo en máquinas virtuales separadas, a través de un tejido de virtualización seguro.
NC Dual Xeon SP4/5-4B
Las configuraciones escalables en un sistema de 1U proporcionan aceleración optimizada para cargas de trabajo en centros de datos locales.
Perfecto para entornos de nube híbrida en informática financiera, aprendizaje automático, almacenamiento computacional y búsqueda y análisis de datos.