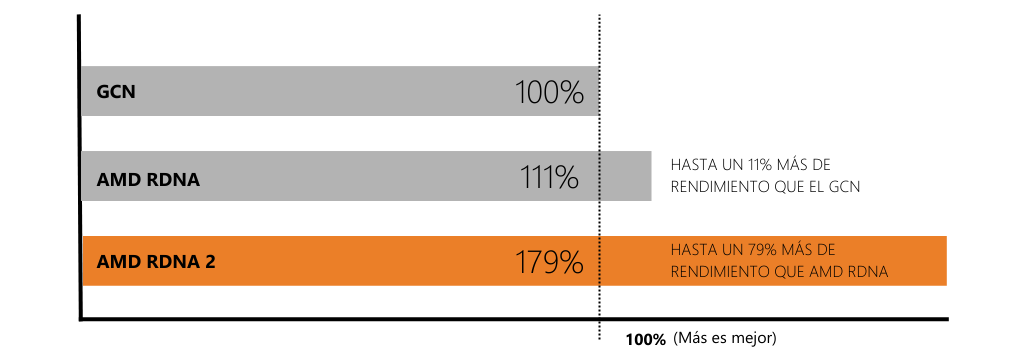Las librerías de procesamiento de datos NVIDIA CUDA-X se integrarán en las soluciones de inteligencia artificial de Azken para acelerar las tareas de preparación y procesamiento de datos que constituyen la base del desarrollo de la inteligencia artificial generativa.
Basadas en la plataforma de cálculo NVIDIA CUDA, las librerías CUDA-X aceleran el procesamiento de una amplia variedad de tipos de datos, lo que incluye tablas, texto, imágenes y vídeo. Entre ellas se incluye la librería NVIDIA RAPIDS cuDF, que acelera hasta 110 veces el trabajo de los casi 10 millones de científicos de datos que utilizan el software pandas utilizando una GPU NVIDIA RTX 6000 Ada Generation en lugar de un sistema basado únicamente en CPU, sin necesidad de modificar el código.
«Pandas es la herramienta esencial de millones de científicos de datos que procesan y preparan datos para la IA generativa. Acelerar Pandas sin cambiar el código será un gran paso adelante. Los científicos de datos podrán procesarlos en minutos en lugar de en horas, y manejar órdenes de grandes magnitudes de datos para entrenar modelos de IA generativa».
Jensen Huang, fundador y CEO de NVIDIA.
Fuente: NVIDIA
Pandas proporciona una potente estructura de datos, denominada DataFrames, que permite a los desarrolladores manipular, limpiar y analizar fácilmente datos tabulares. La librería NVIDIA RAPIDS cuDF acelera pandas para que pueda ejecutarse en las GPU sin necesidad de modificar el código, en lugar de depender de las CPU, que pueden ralentizar las cargas de trabajo a medida que aumenta el tamaño de los datos. RAPIDS cuDF es compatible con librerías de terceros y unifica los flujos de trabajo de GPU y CPU para que los científicos de datos puedan desarrollar, probar y ejecutar modelos en producción sin problemas.
Se espera que NVIDIA RAPIDS cuDF para acelerar pandas sin cambiar el código esté disponible en las soluciones de estaciones de trabajo de IA de Azken con GPU NVIDIA RTX y GeForce RTX próximamente.
La arquitectura de las tarjetas gráficas AMD Radeon™ PRO para workstations
La avanzada arquitectura de las GPU AMD Radeon™ PRO, AMD RDNA, se presentó por primera vez en 2019 y, desde entonces, ha evolucionado hasta convertirse en AMD RDNA 2. Esta arquitectura es la base de los gráficos que alimentan las consolas de juegos y los PC líderes y visualmente enriquecidos. Ahora, AMD RDNA 2 está disponible en la gama profesional de tarjetas gráficas Radeon PRO™ W6000.
La arquitectura gráfica AMD RDNA 2 ofrece más libertad a la hora de trabajar con conjuntos de datos más grandes de manera más rápida.
Mayor rendimiento profesional
Diseñada desde cero con un rendimiento y una eficiencia energética superiores, la arquitectura AMD RDNA 2 ofrece un rendimiento hasta un 194% más rápido respecto a la arquitectura GCN de la generación anterior, con el soporte añadido de Variable Rate Shading (VRS), para un rendimiento de renderizado de fotogramas inteligente, y Vulkan 1.2 y DirectX 12 Ultimate, para un rendimiento gráfico de última generación en software profesional compatible.
Generaciones de arquitectura gráfica
Fuente: AMD
Importancia para el software profesional
La arquitectura AMD RDNA 2 introduce avances significativos en forma de una nueva AMD Infinity Cache. Una unidad de cómputo mejorada, soporte de Raytracing en hardware, combinado con un nuevo pipeline visual para una mayor eficiencia. En el siguiente apartado exploraremos el significado de cada uno de estos términos y, cuando se combinan, cómo estos avances ayudan a conseguir un rendimiento de alta resolución y unas imágenes más vívidas con el software profesional que elijas.
Nueva tecnología AMD Infinity Cache
AMD Infinity Cache
La arquitectura AMD RDNA 2 es más eficiente gracias a la introducción de AMD Infinity Cache. Un nivel de caché adicional totalmente nuevo que permite un rendimiento de gran ancho de banda con bajo consumo y baja latencia, ayudando a eliminar los cuellos de botella de los datos. Esta caché global está contemplada por todo el núcleo gráfico, capturando la «reutilización temporal» (reutilización optimizada e iterativa de los mismos datos) y permitiendo acceder a los datos de forma prácticamente instantánea. Aprovechando los mejores enfoques de procesamiento de datos de alta frecuencia de la arquitectura «Zen», AMD Infinity Cache permite un rendimiento escalable.
Unidades de cálculo mejoradas
Cada unidad de cálculo (CU) del chip alberga varios procesadores de flujo y núcleos. Cuanto mayor es el número de núcleos de una tarjeta gráfica, más potente suele ser. Cada núcleo está duplicado para trabajar en tareas paralelas enviadas desde el software del usuario, como la visualización de imágenes en la pantalla o el cálculo científico. Forman el cerebro central del procesador gráfico.
Trazado de rayos (ray tracing) con aceleración por hardware
Una novedad de la Unidad de Cálculo AMD RDNA 2 es la implementación de una arquitectura de aceleración de trazado de rayos de alto rendimiento conocida como Aceleradores de Rayos, que ofrece un mayor realismo visual en su software compatible. Es un hardware especializado que maneja eficientemente la compleja intersección de cálculos de rayos diseñados para acelerar este proceso, en comparación con el software únicamente.
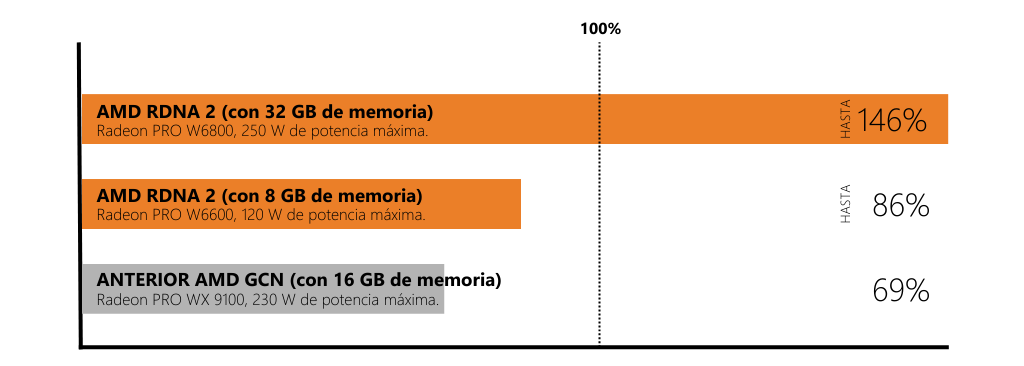
Las últimas GPU con certificación profesional: AMD Radeon™ PRO
AMD Radeon™ PRO cuenta con una arquitectura creada para profesionales
Una arquitectura gráfica es compleja y, además, necesita serlo para las tareas diarias que se lanzan. Estas tecnologías avanzadas de AMD ayudan a eliminar los cuellos de botella habituales de la GPU y el sistema, lo que permite mejorar el rendimiento. Aunque esto suena muy bien, en última instancia lo que importa es el impacto en el software, y en el siguiente gráfico podemos ver solo uno de los muchos ejemplos de aumentos de rendimiento mejorados, pero asequibles, con las GPU AMD Radeon™ PRO, mientras se utiliza menos potencia pico comparativa.
El cambio climático podría tener un impacto crítico en la República de Panamá, donde un importante segmento de la economía depende del funcionamiento del Canal de Panamá. Por ello, se han establecido nuevas estructuras para llevar a cabo investigaciones sobre este impacto. Una de ellas es la nueva infraestructura de clúster de GPU llamada Iberogun.
Situación de Panamá
La República de Panamá está situada en la cordillera más meridional de América Central, al norte de Ecuador. El país está rodeado por el Mar Caribe en el norte y por el Océano Pacífico en el sur, por lo que su clima está determinado principalmente por una atmósfera oceánica cálida y húmeda.
El Canal de Panamá es una de las instalaciones más importantes de Panamá. Los ingresos que generan los cargueros de contenedores a su paso por el mismo suponen alrededor del 40% del Producto Interior Bruto (PIB) del país.
La cantidad de agua del canal depende enormemente de las precipitaciones de su cuenca hidrográfica.
La UTP
La Universidad Tecnológica de Panamá es quien lleva a cabo el estudio y la implementación de este proyecto de la mano del Dr. Reinhardt Pinzón.
La UTP es líder nacional en investigación en el área de ingeniería, además de centro de referencia en innovación tecnológica.
Introducción al estudio de Iberogun
Utilizando el Modelo de Circulación General Atmosférica, del Instituto de Investigaciones Meteorológicas (MRI-AGCM3.2S), se han investigado tanto los futuros cambios climáticos de precipitación en Centroamérica como los cambios climatológicos estacionales en la cuenca alta del Río Chagres, la cual es, a su vez, una subcuenca en el lado oriental de la cuenca del Canal de Panamá.
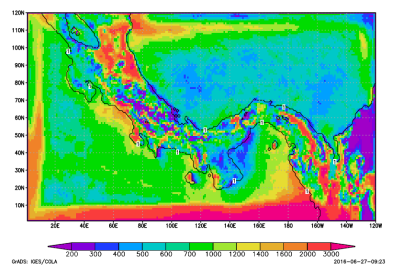
La mayoría de los estudios se han llevado a cabo con el modelo MRI-AGCM3.2S, con simulaciones realizadas en las instalaciones del MRI en Tsukuba, Japón (una visualización de los resultados se representa en la siguiente imagen, que muestra la distribución geográfica en la precipitación de Panamá); pero la idea es que esta capacidad computacional pueda ser utilizada y replicada en suelo panameño desarrollando, de esta forma, un modelo local.
Un posible resultado utilizando una cuadrícula de 2 km de resolución de NHRCM con una situación meteorológica del mundo real que representa la distribución geográfica de las precipitaciones anuales.
A continuación, se analizarán los principales métodos de implementación utilizados en los modelos meteorológicos y climáticos, así como de aceleración de la GPU en términos de optimización.
Métodos de aplicación
Lenguajes específicos de dominio
Los lenguajes específicos de dominio aplicados a los algoritmos Stencil han sido un método para abstraer la placa de paralelización y la disposición de la memoria para el código híbrido GPU/CPU.
> Fortrán híbrido
Fortran es un lenguaje de programación de alto nivel de propósito general, procedural e imperativo, que está especialmente adaptado al cálculo numérico y a la computación científica.
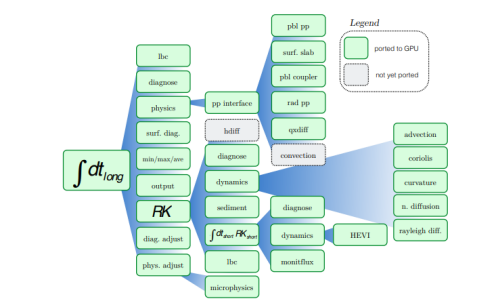
Uno de los métodos evaluados por la UTP es la implementación basada en Fortran híbrido; una transformación de fuente a fuente y una extensión del lenguaje. Esta herramienta presenta un método de división asistida para kernels de gran tamaño que permite la compatibilidad con la GPU en los procesos físicos dentro de los diferentes modelos climáticos sin necesidad de reescribirlos.
Gráfico de llamadas simplificado y estado de la implementación basada en Hybrid Fortran. Al emplear directivas de Hybrid Fortran tanto al núcleo dinámico como a los procesos físicos de los diferentes códigos de usuario, ya se han portado a la GPU casi todos los módulos necesarios para predicción meteorológica operativa.
Directivas
Las directivas se utilizan para orientar a los compiladores sobre cómo optimizar o paralelizar el código ya existente para una arquitectura de hardware específica.
Optimización de la granularidad
La fusión de núcleos ha sido el principal enfoque de optimización de la granularidad aplicado a la programación de la GPU que conocemos.
Transformación de la disposición de la memoria
Aunque los DSL abstraen la disposición de la memoria, también requieren una reescritura completa del código de puntos, pero manteniendo las ganancias de portabilidad de rendimiento de un diseño de memoria abstraído.
Infraestructura Iberogun
Con el objetivo general de desarrollar una infraestructura sostenible para HPC en Panamá, la UTP ha montado una infraestructura de clúster de GPU llamada Iberogun. Basada en 2 servidores DGX 1 (con 16 NVIDIA Tesla P100 cada uno) tiene el objetivo de evaluar posibles modelos climáticos y eventos meteorológicos extremos.
Las tareas que se pretenden desarrollar a través de este proyecto son las siguientes:
Desarrollar e implementar código CUDA para una arquitectura clúster de GPUs.
Estudiar los aspectos atómicos en la formación de la topografía.
Divulgación de los resultados obtenidos.
Prospección de áreas interesantes en simulaciones numéricas en Panamá y Latinoamérica.
Iberogun tiene las siguientes características de salida:
170 tera FLOPS.
GPU 128 GB.
CPU Dual 20-Core Intel Xeon.
NVIDIA CUDA® Cores.
NVIDIA Tensor Cores (en sistemas basados en V100).
Memoria del sistema 512 GB DDR4.
4X 1,92 TB SSD RAID 0.
Independientemente del método utilizado para las proyecciones meteorológicas, los beneficios de su aplicación pueden ser bien recibidos tanto en la comunidad investigadora como en la sociedad en general.
Los modelos que se ajustan a los parámetros del istmo de Panamá pueden ser beneficiosos para la predicción de los ciclos del agua para el área de la cuenca del canal, información muy importante desde las recientes políticas estrictas de uso del agua que se han propuesto y los fenómenos de salinización que se han reportado para la cuenca del canal de Panamá.
Además, los beneficios podrían extenderse a otras áreas de investigación y comercio, tales como: agricultura, generación de energía hidráulica, transporte, ecología y conservación.
Bibliografía
IAHR-APD Congress 2020.
Replicabilidad del clima actual de Panamá en un modelo climático regional no hidrostático anidado en un modelo de circulación general atmosférico.
En el arranque de la GTC sep22, Jensen Huang desvela los avances de la comprensión del lenguaje natural, el metaverso, los juegos y las tecnologías de IA que afectan a sectores que van desde el transporte y la sanidad hasta las finanzas y el entretenimiento.
Los nuevos servicios en la nube para apoyar los flujos de trabajo de IA y el lanzamiento de una nueva generación de GPU GeForce RTX. Estos han sido los protagonistas de la conferencia magistral de la GTC sep22 de NVIDIA; que ha estado repleta de nuevos sistemas y softwares.
La computación está avanzando a velocidades increíbles. El motor que impulsa este cohete es la computación acelerada y su combustible es la IA.
Jensen Huang, CEO de NVIDIA.
Huang relacionó las nuevas tecnologías con nuevos productos y nuevas oportunidades; desde el aprovechamiento de la IA para deleitar a los jugadores con gráficos nunca vistos, hasta la construcción de campos de pruebas virtuales donde las mayores empresas del mundo puedan perfeccionar sus productos.
Las empresas obtendrán nuevas y potentes herramientas para aplicaciones de HPC con sistemas basados en la CPU Grace y el superchip Grace Hopper. Los jugadores y creadores obtendrán nuevos servidores OVX impulsados por las GPU Ada Lovelace L40 para centros de datos. Los investigadores y científicos informáticos obtendrán nuevas funciones de modelos de lenguaje de gran tamaño con el servicio NeMo de NVIDIA LLM. Y la industria automovilística recibe Thor, un nuevo cerebro con un asombroso rendimiento de 2.000 teraflops.
Huang destacó cómo importantes socios y clientes de una variedad de sectores están implementando las tecnologías de NVIDIA. Por ejemplo, Deloitte, la mayor empresa de servicios profesionales del mundo, va a ofrecer nuevos servicios basados en NVIDIA AI y NVIDIA Omniverse.
Un «salto cuántico» en esta GTC sep22: GPU GeForce RTX 40 series
Lo primero que se presentó en la GTC sep22 fue el lanzamiento de la nueva generación de GPU GeForce RTX Serie 40 con tecnología Ada, que Huang calificó de «salto cuántico» que allana el camino a los creadores de mundos totalmente simulados.
Fuente: NVIDIA
Huang presentó a su audiencia Racer RTX, una simulación totalmente interactiva y enteramente trazada por rayos, con toda la acción modelada físicamente.
Los avances de Ada incluyen un nuevo multiprocesador de flujo, un nuevo RT con el doble de rendimiento de intersección de rayos y triángulos y un nuevo Tensor Core con el motor de transformación Hopper FP8 y 1,4 petaflops de potencia de procesamiento tensorial.
Ada también presenta la última versión de la tecnología NVIDIA DLSS: DLSS 3. Que utiliza la IA para generar nuevos fotogramas comparándolos con los anteriores para entender cómo está cambiando una escena. El resultado: aumentar el rendimiento de los juegos hasta 4 veces con respecto al renderizado por fuerza bruta.
DLSS 3 ha recibido el apoyo de muchos de los principales desarrolladores de juegos del mundo, con más de 35 juegos y aplicaciones que han anunciado su compatibilidad.
DLSS 3 es uno de nuestros mayores inventos en materia de renderizado neuronal
Jensen Huang, CEO de NVIDIA.
Una nueva generación de GPU GeForce RTX
Esta tecnología ayuda a ofrecer 4 veces más rendimiento de procesamiento con la nueva GeForce RTX 4090 frente a su precursora, la RTX 3090 Ti. La nueva «campeona de los pesos pesados» tiene un precio inicial de 1.599 dólares y estará disponible el 12 de octubre.
Además, la nueva GeForce RTX 4080 se lanzará en noviembre con dos configuraciones:
La GeForce RTX 4080 de 16 GB, con un precio de 1.199 dólares, tiene 9.728 núcleos CUDA y 16 GB de memoria Micron GDDR6X de alta velocidad. Con DLSS 3, es dos veces más rápida en los juegos actuales que la GeForce RTX 3080 Ti, y más potente que la GeForce RTX 3090 Ti a menor potencia.
La GeForce RTX 4080 12GB tiene 7.680 núcleos CUDA y 12 GB de memoria Micron GDDR6X, y con DLSS 3 es más rápida que la RTX 3090 Ti, la GPU insignia de la generación anterior. Su precio es de 899 dólares.
Otra novedad de esta GTC sep22 es que NVIDIA Lightspeed Studios utilizó Omniverse para reimaginar Portal, uno de los juegos más célebres de la historia. Con NVIDIA RTX Remix, un conjunto de herramientas asistidas por IA, los usuarios pueden modificar sus juegos favoritos, lo que les permite aumentar la resolución de las texturas y los activos, y dar a los materiales propiedades físicamente precisas.
Fuente: NVIDIA
Impulsando los avances de la IA: la GPU H100
Relacionando los sistemas y el software con las tendencias tecnológicas generales, Huang explicó que los grandes modelos de lenguaje, o LLM; y los sistemas de recomendación son los dos modelos de IA más importantes en la actualidad.
Y los grandes modelos de lenguaje basados en el modelo de deep learning Transformer, presentado por primera vez en 2017, se encuentran ahora entre las áreas más vibrantes para la investigación en IA y son capaces de aprender a entender el lenguaje humano sin supervisión o conjuntos de datos etiquetados.
Un solo modelo preentrenado puede realizar múltiples tareas, como la respuesta a preguntas, el resumen de documentos, la generación de textos, la traducción e incluso la programación de software. Hopper está en plena producción y pronto se convertirá en el motor de las fábricas de inteligencia artificial del mundo
Jensen Huang, CEO de NVIDIA.
Grace Hopper, que combina la CPU Grace para centros de datos basada en Arm con las GPU Hopper, con su capacidad de memoria rápida 7 veces mayor, supondrá un «salto de gigante» para los sistemas de recomendación. Los sistemas que incorporen Grace Hopper estarán disponibles en el primer semestre de 2023.
Tejiendo el metaverso: la GPU L4
La próxima evolución de internet, denominada metaverso, se ampliará con el 3D.
Omniverse es la plataforma de NVIDIA para crear y ejecutar aplicaciones del metaverso. La conexión y simulación de estos mundos requerirá nuevos ordenadores potentes y flexibles. Y los servidores OVX de NVIDIA están pensados para escalar estas aplicaciones. Los sistemas OVX de segunda generación de NVIDIA estarán equipados con las GPU para Ada Lovelace L40.
Thor para vehículos autónomos, robótica, instrumentos médicos y más
En los vehículos actuales, la seguridad activa, el aparcamiento, el control del conductor, las cámaras de los retrovisores, el clúster y el ordenador de a bordo son gestionados por distintos ordenadores. En el futuro, estarán a cargo de un software que mejorará con el tiempo y que se ejecutará en un ordenador centralizado.
Y en este sentido, Huang presentó DRIVE Thor, que combina el motor transformador de Hopper, la GPU de Ada y la sorprendente CPU de Grace.
El nuevo superchip Thor ofrece 2.000 teraflops de rendimiento, sustituyendo a Atlan en la hoja de ruta de DRIVE; y proporcionando una transición perfecta desde DRIVE Orin, que tiene 254 TOPS de rendimiento y se encuentra actualmente en los vehículos de producción.
Thor será el procesador para la robótica, los instrumentos médicos, la automatización industrial y los sistemas de inteligencia artificial de vanguardia.
Jensen Huang, CEO de NVIDIA.
3,5 millones de desarrolladores, 3.000 aplicaciones aceleradas
Existe un ecosistema de software con más de 3,5 millones de desarrolladores que están creando unas 3.000 aplicaciones aceleradas utilizando los 550 kits de desarrollo de software, o SDK, y los modelos de IA de NVIDIA. Y está creciendo rápidamente. En los últimos 12 meses, NVIDIA ha actualizado más de 100 SDK y ha introducido 25 nuevos.
Los nuevos SDK aumentan la capacidad y el rendimiento de los sistemas que ya poseen nuestros clientes, al tiempo que abren nuevos mercados para la computación acelerada.
Jensen Huang, CEO de NVIDIA.
Nuevos servicios para la IA y los mundos virtuales
Basados en la arquitectura de transformadores, los grandes modelos lingüísticos pueden aprender a entender significados y lenguajes sin supervisión ni conjuntos de datos etiquetados, lo que desbloquea nuevas y notables capacidades.
Para facilitar a los investigadores la aplicación de esta «increíble» tecnología, Huang anunció Nemo LLM, un servicio en la nube gestionado por NVIDIA que permite adaptar los LLM preentrenados para realizar tareas específicas. Y para acelerar el trabajo de los investigadores de fármacos y biociencia, también se anunció BioNeMo LLM, un servicio para crear LLMs que comprendan sustancias químicas, proteínas y secuencias de ADN y ARN.
Huang también detalló NVIDIA Omniverse Cloud; una infraestructura que conecta las aplicaciones Omniverse que se ejecutan en la nube, en las instalaciones o en un dispositivo.
Los nuevos contenedores de Omniverse ya están disponibles para su implantación en la nube :
Replicator. Para la generación de datos sintéticos.
Farm. Para el escalado de granjas de renderizado.
Isaac Sim. Para la construcción y el entrenamiento de robots de IA.
Omniverse está siendo adoptado e implementado por importantes compañías en todo el mundo:
Lowe’s. Tiene casi 2.000 puntos de venta, utiliza Omniverse para diseñar, construir y operar gemelos digitales de sus tiendas.
Charter, proveedor de telecomunicaciones de 50.000 millones de dólares; y HeavyAI, proveedor de análisis de datos interactivos. Están utilizando Omniverse para crear gemelos digitales de las redes 4G y 5G de Charter.
GM. está creando un gemelo digital de su estudio de diseño de Michigan en Omniverse, en el que pueden colaborar diseñadores, ingenieros y comercializadores.
Lowe’s está utilizando Omniverse para diseñar, construir y operar gemelos digitales de sus tiendas. Fuente: NVIDIA
Nuevo Jetson Orin Nano para robótica
Jensen Huang anunció también Jetson Orin Nano, un diminuto ordenador para robótica que es 80 veces más rápido que el anterior y superpopular Jetson Nano.
Jetson Orin Nano ejecuta la pila de robótica NVIDIA Isaac y presenta el marco acelerado por GPU ROS 2, y NVIDIA Iaaac Sim, una plataforma de simulación de robótica.
Nuevas herramientas para servicios de vídeo e imagen
La mayor parte del tráfico mundial de Internet es vídeo, y los flujos de vídeo generados por los usuarios se verán cada vez más aumentados por efectos especiales de IA y gráficos por ordenador, explicó Huang.
Los avatares se encargarán de la visión por ordenador, la inteligencia artificial del habla, la comprensión del lenguaje y los gráficos por ordenador en tiempo real y a escala de la nube
Jensen Huang, CEO de NVIDIA.
Para posibilitar nuevas innovaciones en la intersección de los gráficos en tiempo real, la IA y las comunicaciones, Huang anunció que NVIDIA ha estado creando librerías de aceleración como CV-CUDA, un motor de ejecución en la nube llamado UCF Unified Computing Framework, Omniverse ACE Avatar Cloud Engine y una aplicación de muestra llamada Tokkio para avatares de atención al cliente (chatbots).
GTC sep22: esto es solo el comienzo
En la GTC sep22 hemos anunciado nuevos chips, nuevos avances en nuestras plataformas y, por primera vez, nuevos servicios en la nube. Estas plataformas impulsan nuevos avances en IA, nuevas aplicaciones de IA y la próxima ola de IA para la ciencia y la industria
La criomicroscopía electrónica es una técnica muy utilizada en el campo de la biología para el estudio de estructuras moleculares a temperaturas criogénicas; lo que permite observar las muestras a resolución atómica.
Jackes Dubochet, Joachim Frank y Richard Henderson ganaron el Premio Nobel de Química por su trabajo en el desarrollo de la criomicroscopía electrónica en el año 2017.
La metodología que sigue esta técnica es la siguiente:
La muestra se congela y se prepara con hielo vítreo.
Se realiza la toma de imágenes.
Se digitalizan las imágenes.
Las imágenes ya digitalizadas en 2D se procesan para obtener una reconstrucción 3D de las estructuras macromoleculares.
Los avances tecnológicos (como los microscopios que trabajan, entre otras cosas, con GPUs que aceleran el procesamiento de imágenes) y la evolución en la potencia de cómputo han facilitado la elaboración de los modelos tridimensionales.
El servicio de criomicroscopía electrónica
Con sede en el Centro Nacional de Biotecnología (CNB), la instalación de criomicroscopía electrónica (Cryo-EM) del CSIC es un servicio básico de última generación que ofrece tanto la preparación de muestras como la recopilación de imágenes Cryo-EM de material biológico.
La instalación alberga dos criomicroscopios electrónicos:
Un JEOL CryoARM de 300 kV equipado con un cargador automático, un detector de electrones directos Gatan K3 y un filtro de energía Omega.
Un FEI TALOS Arctica de 200 kV, equipado con un cargador automático y un detector de electrones directos Falcon III.
Ambos son adecuados para la recopilación de grandes cantidades de datos de alta resolución.
Esta instalación, única en España, cuenta también con dos dispositivos adecuados para la vitrificación de muestras pequeñas, como proteínas y complejos macromoleculares y un tercer dispositivo adecuado para la congelación rápida de muestras celulares.
“El primer paso de esta técnica (la criomicroscopía electrónica) consiste en congelar las proteínas a muy baja temperatura (-180ºC), de tal manera que movilizamos las proteínas en una capa fina de hielo, quedando inmersas y dispuestas en distintas orientaciones.
Posteriormente, introducimos las proteínas en el microscopio electrónico de transmisión y capturamos un gran número de imágenes que, gracias a potentes ordenadores, muestran la estructura de estas proteínas en alta resolución. Incluso, podemos visualizar los aminoácidos que componen estas proteínas.
Con la utilización de esta técnica ayudamos al desarrollo de nuevos fármacos”.
Rocío Arranz, jefa del Servicio de Criomicroscopía Electrónica del Centro Nacional de Biotecnología del CSIC (CNB-CSIC)
BREM
El Basque Resource for Electron Microscopy (BREM) proporciona acceso a instrumentación de alta gama y experiencia en criomicroscopía electrónica de alta resolución (Cryo-EM) a investigadores nacionales e internacionales, académicos e industriales.
Está ubicado en el Instituto de Biofisika (CSIC) en el parque científico de la Universidad del País Vasco en Leioa; y está apoyado por la fundación Biofísica Bizkaia. Es parte de una iniciativa ambiciosa del Departamento de Educación y el Fondo de Innovación del Gobierno Vasco para incorporar tecnologías disruptivas que tengan un impacto importante en el desarrollo tecnológico, de investigación y de innovación.
El objetivo de BREM es comprender la base estructural de los procesos biológicos y la patogénesis de las enfermedades humanas a través de la criomicroscopía electrónica.
Además, también apoya los esfuerzos de investigación de fármacos basados en biología estructural y el desarrollo de terapias avanzadas para enfermedades.
BREM ha instalado un microscopio electrónico de transmisión Thermo Fisher Titan Krios G4; es el primero en España y el segundo en el sur de Europa. Cuenta con personal altamente cualificado y ayuda a los usuarios con la determinación de la estructura tridimensional utilizando todas las técnicas principales Cryo-EM disponibles para la biología estructural.
«La llegada de este microscopio electrónico al Instituto Biofisika nos permite participar en proyectos internacionales de interés biomédico; por lo tanto, podemos competir y posicionar al País Vasco en una primera línea en biología estructural».
David Gil Carton, director técnico de BREM
Características del criomicroscopio electrónico de BREM
El criomicroscopio electrónico instalado en el Instituto Biofisika para la observación de especímenes biológicos a baja temperatura mediante criomicroscopía electrónica tiene las siguientes características:
Se trata de un criomicroscopio electrónico de transmisión de 300 kV de alta resolución de última generación.
Utiliza lentes de alta estabilidad y un cañón de emisión de campo como fuente de iluminación.
Cuenta con una placa de fase para la mejora del contraste.
Incluye un filtro de energía y un detector directo de electrones como sistema de recogida de información.
Está optimizado para el análisis automatizado de partículas individuales, microdifracción de electrones y la tomografía electrónica de doble eje.
Consigue imágenes de muestras biológicas a baja temperatura con una resolución ultra alta para la adquisición de datos con un alto rendimiento y reproducibilidad; y de manera simple e intuitiva.
La aportación de Azken a la criomicroscopía electrónica
BREM planteó un reto a Azken Muga:
“El éxito de este microscopio es su gran capacidad de automatización, la mejora en estabilidad y el mayor rendimiento de los nuevos detectores.
Todo esto hace posible realizar sesiones ininterrumpidas de 48 horas de un solo experimento. Estos datos pueden ser 10, 20 o 40 Tb, dependiendo del experimento; luego, tanto el control de calidad para toma de decisiones en tiempo real («processing on-the-fly») como la transferencia de datos a los usuarios lo más rápido -y sin fallos- es vital para el éxito de BREM.
Los datos son movies (vídeos) de 1 Gb cada uno en formato MRC o TIFF y en un solo experimento hay que transferir al usuario desde 20.000 hasta 45.000 de estas movies. El microscopio puede generar 10.000 movies en 24 horas”.
David Gil Carton, director técnico de BREM
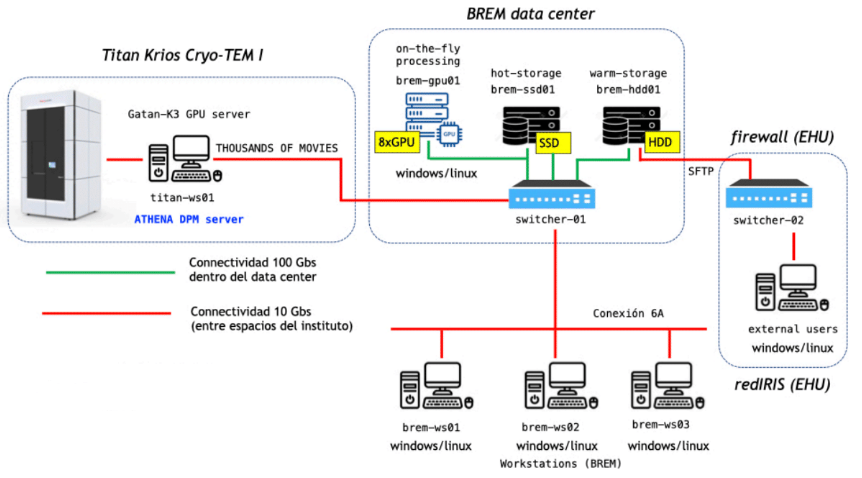
BREM requería por parte de Azken un data center, compuesto por un servidor 8xGPU, dos servidores de almacenamiento y tres workstations, conectado al servidor del microscopio. Siguiendo este esquema:
Fuente: BREM
Los sistemas elegidos para llevar a cabo este proyecto fueron: un servidor basado en GPU para el procesamiento de imágenes (8G4 Dual Xeon Scalable HPC 8xGPU); un servidor de almacenamiento SSD (RStorage 540S Dual Xeon Scalable Processors 36xSSD); un servidor de almacenamiento HDD (RStorage 540S Dual Xeon Scalable Processors 36xHDD); y tres workstations multi GPU de escritorio (T-Series Xeon SP).